
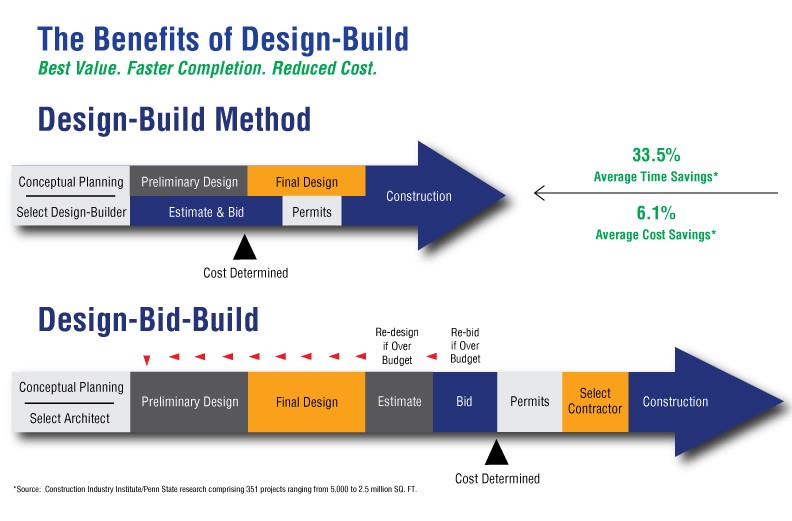
0. The Road So Far…
In case you just came back from Mars, the whole ISO 19650 is being restructured and revised, with some terminological changes that caused quite a stir and, most importantly, a whole different approach that aims at treating design & construction as a whole process together with operations. I wrote about it here.
What worried me mostly, if you remember, was the lack of detail on how to deal with Information Management through the very different stages of inception, design, tendering, post-tendering, construction, handover. And if I’m leaving out operations is just because that stage already has guidance, in the forms of norms on Asset and Facility Management. Those details were left to the upcoming part 3. Well, now part 3 is here. Let’s see what it says.

1. Declaration of Intent
At a first glance, this is precisely what Part 3 does:
- the previous requirements, focused on the operation stage, aren’t a portion of part 3 any longer;
- Part 3 contains guidance on the implementation of the requirements of ISO 19650-2 under what are defined “various circumstances”: multiple trigger events, scalability depending on the complexity of the project and the team, various procurement forms;
- Part 3 provides guidance on some specific requirements regarding the Common Data Environment, the aggregation of information models, compilation of information, standards, procedures and methods to create information, and information requirement depth.

2. Trigger Events (clause 6)
Trigger Events are defined, at a very high level, as any event, happening at any point of the asset’s lifecycle, that changes or will change the asset from a physical or an abstract point of view, meaning that asset information will have to be updated.
The principle, in theory, is good, and examples are given in trying to clarify the broadness of the approach:
- inspections, surveys, maintenance, repairs, components or equipment being replaced are trigger events during the regular lifecycle or an asset;
- retrofitting, decommissioning, renovations and so on, for an existing asset that needs work, or creation for new constructions.
To complicate things, triggering events can be planned or unplanned, even unforeseeable, though no specification is given as to how to prepare to capture unplanned triggering events such as extraordinary maintenance after damaging events. You’ll have to figure it out.

Given examples of planned triggering events are all in the domain of maintenance, but new construction (labelled information creation) is left to its own devices: the norm just says you’ll have to split delivery into stages. Again, no shit.
Unplanned triggering events, of course, are all in the domain of emergencies, and it’s specified that, in case of a fire, you might want to put it off before recording information about it. In other words, information production can be commissioned after the unfolding of what the trigger events… well, triggered.
There’s an additional focus, that’s Trigger Events for Asset Acquisition, and the text states it “differs from planned and unplanned triggering events because it only involves the participation of the information requester in a real estate transaction”. The idea is that the acquiring owner defines the needed information internally (though, being in the context of portfolio management, maybe they should already know that?), and requests them to the one that’s selling. Since someone at the ISO table probably works in Real Estate, the text specifies that the existing owner can “decide whether to respond to the information requirements […] as part of the asset acquisition transaction”. If the selling party decides not to provide the information, because they’re either unable or unwilling, the acquiring party needs to treat this as an unplanned trigger events, for some reason, and initiate the process of acquiring the information.
3. Scalability (clause 7)
As a general prnciple, the scalability addresses the overuse of the expression “shall consider,” throughout the norm, which is generally not necessary because the word “shall” should be used in a norm with a very specific meaning. Apparently, this is not the case, and “might consider” could probably have been a far more accurate verbal choice. A first discretional tool whether to consider information management or not is provided by Table 2. In a nutshell, complexity is evaluated based on 4 parameters:
- timeframe, and here we have a very clear idea of why you can’t throw everything into the same framework, because we’re forced to consider in the same text events that span hours (the replacement of light bulbs), weeks and months, years or many decades;
- cost, scope or risk, spanning from “very low and very small” and very high or very large”, whatever the fuck that means;
- organisational structure, which is correctly taken into account as a factor for the complexity but unfortunately opens up to the idea, already present in the 2018 version of part 2, that we might have concurrent lead appointed party. You might have to place them in a cage and let them fight it out.
- number of information creation requirements or milestones, again throwing together the complexity of requirements and the length of a project, for a reason that escapes me.
These parameters divide projects in a rather childish way, spanning from very small to large and major programs.

3.1. Scalability based on Project Dimensions
3.1.1. Very Small Projects
Scenario: you and your cousin are changing the lightbulbs in the grand hall, while your mother inputs data into the model of your house through her iPad. Or something like that.
In this scenario, the team can be decribed in text form, you don’t need an information container breakdown structure, there’s no testing for the information sharing process and the schedule can be simple, only consisting of a single entry. There’s even a scenario in which the information requester, the lead appointed party and the appointed party are a single person.

3.1.2. Small Projects
Mama wants to repaint your living room, so you and your brother look for a professional painter while you’re trying to convince your mother to pick a colour. Annex B provides a scenario for such a project.
The team is created by multiple parties: the contractor is the lead appointed party and has to deliver a responsibility matrix, and you’ll need a simple breakdown structure, that can be discipline-aligned, split by physical division of the asset or by some other characteristics.
3.1.3. Large Projects
Multiple organizations or actors might be responsible for providing resources for the different stages of such project, identified as initiation, control and financing of the asset-related project (with again no mention or attention to production). Some important things happen when it comes to these kind of projects, which are the majority of new constructions:
- the norm backpedals on the idea that you should start with information requirements at an organisational level and accepts that, given the extended timeframe of a large project, you might start with no complete picture of information requirements throughout all stages: you start half-assed, and figure it out as you go along;
- there’s an acceptance and encoding of leadership instability at an information management level, stating that “the persons involved in certain information management activities or information creation activities will likely change,” and parties should include a succession planning in their texts, thus creating a brand new figure: the BIM Heir;
- coordination is crucial, but there’s no tool or framework or guidance on what do we mean by coordination, who should coordinate what and when.
There’s no example for this scenario.
3.1.4. Humongous Projects (Major Programs)
A program is defined, in alignment with many project management frameworks including Axelos, as a series of correlated projects. This leads to a complicated organisational structure, of course, and many information models being delivered across different timeframes and through different milestones.
All the norm says, is that you should be able to treat this by considering each portion as a large-scale project and manage accordingly. No mention, for instance, to change management, that needs to be a structural role in a project spanning years, nor to any other specific consideration.
I want to scream.

3.2. Scalability based on Team Complexity
Another factor that’s provided as a lens to define scalability is how many appointed parties you have or, as they would say in Dirk Gently, how many sets of guys are involved in the situation. And here the norm again insists that the information requester can assemble how many lead appointed parties they choose.

The fact that ylou have multiple people, even in parallel, and they’re all leading, and no one is leading the leaders, is never indicated as a source for confusion because, of course, the norm assumes that you, being the information requirer, are the general leader. Except usually you need one of the suppliers to be the lead because you weren’t able to lead them yourself in the first place.
Anyway, this is where things get tricky.
3.2.1. Team Scenario 1: no formal agreement
More than scalability, we’re in section 8 and it addresses how information should be managed when no formal information order exists between organizations, a scenario that, as far as I’m concerned, should be discouraged instead of supported but here we are.
The framework distinguishes between two types of information orders:
- Formal orders, established between separate organizations;
- Informal orders, established between different parts of the same organization.
In this situation, for reasons that are completely obscure to me, it’s stated that the information requester should be a third-party between the client who needs the information and the supplier who’s supposed to provide it outside of a formal agreement. All hail the third-party consultant.
This gold-plated guy should:
- determine what information the external organization actually needs
- identify specific information requirements
- establish information constraints
- translate external demands into internal information creation requirements
- serve as a quality control and accountability checkpoint
This all looks very formal, for something that’s not formal.

The norm gives two practical examples of where this might occurr. One makes sense. The other, not so much. The one that makes sense: the landscape architect needs information from a bridge engineer but they have no formal agreement between each other. In Italy and the UK, we solved this through a Framework for Collaborative Agreement, which means we recognised the need to create an agreement, and the framework has an enormous, documented success.
No, no, says the ISO: we don’t need an agreement.

The second scenario is even worst: the local authority needs information from a designer in order to verify whether they can grant a building permit. Though the designer isn’t contractually bound to the local authority, the local authority can (and should) mandate information requirements, which is an even higher form of agreement. Except we’re saying they shouldn’t. They should have a third-party mediator instead.
In the public procurement scenario, this third-party consultant needs to:
- determine what the local authority needs (purposes, requirements, and constraints)
- incorporate these requirements into the information creation requirements for the relevant lead suppliers;
- make a critical distinction wherfe external constraints from the local authority become acceptance criteria within the internal information creation requirements, which is ncie;
- safeguard against the non-transparent employment of subcontractors for information production, which is a deviation the framework and must be specifically agreed upon;
- manage the whole process by keeping the client in the loop.
Basically, instead of pushing for public procurement literacy, we’re encoding their dependence upon third-parties. Shame.

3.2.2. Scenario 2: teams of different sizes
Since giving examples for various sizes was apparently too much work, and it’s not like it’s the job of this norm, section 8.3 decides to give two useless examples: the team of one person (yeah, seriously) and a vaguely defined large team.
I won’t insult your intelligence by explaining how the ISO tries to tell you to work, when you’re by yourself. Please do yourself a favour and refer to ISO 9001 for that.
The large team, on the other hand, operates in a scenario with a programme that will result in the 50-years concession of a railway, with more than 100 teams, 20 of them active in the construction and operation stage (bundled together, of course). A scenario with which many people will be able to relate, I’m sure. The bottom line of this seems to be: you need a professional information manager.

There’s no in-between, no information on how to manage when you have, I don’t know, a hospital with three engineering companies and an architectural firm, that need to handover the model to a general contractor with their subcontractors, some of them working in BIM and others not up to speed. You’ll have to come up for a way, I guess. As we’ve always done.
4. Procurement Forms (clause 9)
Aside from the scenario in which there’s no agreement, for other procurement frameworks the text refers to other norms: ISO 6082: 2025 Construction project governance – Guidance on delivery management, ISO 10845-1: 2020 Construction procurement – Part 1: Processes, methods and procedures, and ISO 22058: 2022 Construction procurement – Guidance on strategy and tactics, with the due note that these frameworks refer to large construction projects. After practically no attention to design and construction, this is where we expect to get some guidance from the text.
4.1. Design and Build
This is a standard approach in many countries: instead of having a set of guys desiging the asset, a bidding process, and then a contractor takes over, a single actor is managing both the design and the construction, ideally shortening the process and incorporating buildability since the earlier stagbes of the process. This, as I’ve been saying for many years now, is now ideal under many points of view but it’s the preferrable scenario when it comes to BIM.
Trying my best to be practical, and using numbers from Part 2, this means that:
- the client should have an information management strategy at the organisational level, (5.1) and they need to have the asset information model (5.2);
- at the beginning of the project, the client should implement the project initiation stage (5.3);
- the client should perform Appointment preparation (5.4), evaluate the request responses (5.5.9), and complete the lead appointed party’s appointment (5.6.5) to the appointment of each lead appointed party (which, of course, might be more than one because we don’t want to hurt anybody’s feelings);
- each lead appointed party should:
- during the selection stage: prepare an information management assignment matrix (5.5.1), an information production plan (5.5.2) and an information production assignment matrix (5.5.3), prepare a summary of the information producton team’s capabiloity and capacity (5.5.5), an information production mobilisation plan (5.5.6), an information production risk assessment (5.5.7), and compile the request response (5.5.8);
- during the appointment stage: confirm the request response (5.6.1) because of course we want to keep the situation where you promised something during selection, to get the job, but then you change your mind once you’ve been selected; establish the lead’s information requirements (5.6.2), establish the information production schedule (5.6.3), and establish requirements for any additional reference information (5.6.4), assemble a set of information production requirements for each appointed party (5.6.6), assemble an information production schedule for each appointed party (5.6.7), and complete each appointed party’s appointment (5.6.8);
- during the mobilisation stage: mobilise enabling technologies (5.7.1), test the information production methods and procedures (5.7.2), and mobilise resources (5.7.3);
- an assessment of capability and capacity (5.5.4) needs to be performed by clients while selecting their lead appointed party, and collaborate with them in establishing the information production schedule (5.6.3) prior to confirmation of the appointment, and collaborate with their lead appointed party in doing what was described for the mobilisation phase (technologies, testing and resources);
- during the information production stage, as long as they produce information and share it with other members of the team, each appointed party needs to verify reference information and shared resources (5.8.1), generate and coordinate information (5.8.2), check their information containers (5.8.3), review and approve them (5.8.4);
- verification during production needs to be performed by the client at the request of the lead, which I hope it means according to a schedule;
- the lead appointed party should review and comment on information models (5.8.6) in collaboration with their suppliers whenever the team needs to verify the information, which is a weird way of putting it, because it looks a lot like BIM coordination (and validation) on demand, and I can see loads of subcontractors who’ll never want you to check their stuff;
- lead appointed parties need to review and authorise information models (5.8.7) whenever the team is ready to submit them to the client for acceptance, which is refreshing;
- the client, on their side, needs to review and accept the information container (5.8.8), and aggregate the information model into an asset information model that somehow already exists (5.8.9);
- upon project completion, the client archives all information models produced during the project (all that they know about, at least), and publishes all lessons learned captured during the project, though we don’t know how they were captured since there’s no mention of this during the information production stage (and these were 5.9.1 and 5.9.2).
If this looks confusing, thank me: the original text doesn’t provide it with such clarity, but only mentions the numbers in a way such as “X and Y should apply 5.8.8 to 5.8.9”, expecting you to flip back and forth from the two norms. I did that for you. I want a beer.
4.2. Design-Bid-Build
This is the evil twin, and the standard when it comes to public procurement (at least in Italy): a dude works out the design, submits it to the client, the client bids to the contractor and finds another dude. The two dudes almost never talk to each other. This means the process is split in two: the designer has a lead, and the contractor will have another lead. The client has much more agency in the process. Here’s how part 3 puts it, again using numbers from part 2.
- again, the client should develops the organisational strategy (5.1) and has their own asset information model (5.2), which nobody’s producing because in any tendering projects so far it’s either you already have it or you go rogue and develop it outside contractual requirements;
- the project is initiated (5.3) by the client (no shit);
- the client prepares for the appointment (5.4) and then we skip to the selection phase: they evaluate the request responses (5.5.9), and completes the lead’s appointment (5.6.5);
- each lead:
- during the selection phase, prepares the information management assignment matrix (5.5.1), the information production plan (5.5.2) and the information production assignment matrix (5.5.3), a summary of the information production team’s capability and capacity (5.5.5), an information production mobilisation plan (5.5.6), an information production risk assessment (5.5.7), and eventually compiles the request response (5.5.8);
- during the appointment phase, confirms the request response as before (5.6.1), establishes information requirements as the lead (5.6.2), the information production schedule (5.6.3), requirements for any additional reference information (5.6.4), asembles a set of information production requirements (5.6.6) and the schedule (5.6.7) for each appointed party, and completes their appointment (5.6.8);
- during the mobilisation stage, again mobilises enabling technologies (5.7.1), tests the information production methods and procedures (5.7.2), and mobilises the resources (5.7.3);
- during the selection, each prospect appointed party should participate in the assessment of their capability and capacity (5.5.4), and collaborate with its lead in establishing the production schedule prior to confirmation of the appointment (for free, I’m assuming), on top of collaborating through the mobilisation phase;
- during the production stage, each appointed party is expected to verify reference information and shared resources (5.8.1), generate and coordinate information (5.8.2), check information containers (5.8.3), review and approve information containers (5.8.4) as long as they’re creating information and sharing them with other members of the production team (which begs the question: what’s the lead doing?);
- the client’s the one to review and comment on information containers (5.8.5), again at the request of a lead that hasn’t checked anything so far, which is a weird sequence to place this;
- each lead reviews and comments on information models too (5.8.6), in collaboration with its providers and again on demand;
- each lead also reviews and eventually authorises models (5.8.7) whenever the team is ready to submit them for acceptance, which probably means that the client can take a look and review models before official submission but only if you ask nicely?
- the client eventually reviews and accepts models (5.8.8), aggregates them into the asset information model produced by Santa Clause and his elves (5.8.9);
- upon project completion, the client again archives all information models (5.9.1) and publishes lessn learned (5.9.2) after all lead appointments have been completed.
What’s the difference? It’s tough to say, since the tendering process between design and build doesn’t explicitly appear into the schedule, nor there’s a participation of the lead appointed party from the design stage in preparing documentation for the selection and appointment of the lead from the construction stage, as it often happens. The main differences might be summarises as follows, though the norm doesn’t do this (and I might have missed some points, given how obscure is the text with all its references).
- Team Structure: Design-and-Build has a single integrated team (even given the possibility of multiple leads because we like it complicated), while Design-Bid-Build separates design and construction into two disconnected processes (though we don’t know how);
- Client Oversight: Design-Bid-Build gives the client more review points throughout production (particularly step 5.8.5), while Design-and-Build limits client involvement mostly to final acceptance;
- Lead Authority: Design-and-Build leads have more autonomy in authorising information before submission through the process; Design-Bid-Build leads seem to have authority to submit them only at the end of a given process;
- Supplier Participation: Design-Bid-Build requires prospect suppliers to participate in capability assessment collaboratively, while Design-and-Build is client-led assessment (is it though?).
4.3. Integrated Project Delivery
Though this is possibly the aim of BIM, this framework doesn’t get the same level of detail as design-build and design-bid-build: all that’s said is that IPD is possible through separate arrangements with sub-signatories (possibly the collaborative frameworks I was mentioning earlier), but in practice it says they should nominate a lead, and gives no further guidance (’cause we don’t care about the production stage, that much is clear). All that matters is the relationship with the client. To the ISO, that is. And here I thought the owner was a part of IPD. Silly me.
4.4. Frameworks and Long-Term Agreements
This is the kind of relationship that’s bound to be more relevant for maintenance and, since this seems to be the major focus of this norm, you’d think the guidance would be more solid. In practice, it follows the same road as the other:
- the organisational level stays the same: you have your strategy (5.1) and you have your asset information model (5.2) which, at least for maintenance, totally makes sense;
- the initiation stage (5.3) is carried out as usual, and so is the preparation for appointment (5.4);
- the client evaluates responses to the request for bidding (5.5.9), and appoints a lead (5.6.5): this of course means that each lead has prepared the information management assignment matrix (5.5.1), the information production plan (5.5.2) and the information production assignment matrix (5.5.3), the summary of the team’s capability and capacity (5.5.5), the mobilisation plan for producing information (5.5.6), the information production risk assessment (5.5.7), and has compiled the request response (5.5.8);
- during the appointment stage, each lead confirm the reques response (5.6.1), establishes their own information requirement for the subcontractors (5.6.2), establishes the schedule for information production (5.6.3) and the requirements for any additional reference information (5.6.4), assembles the set of informatiuon production requirements for each appointed party (5.6.6), the relative information production schedule (5.6.7) and completes the appointments (5.6.8);
Note: what’s weird to me, in any agreement framework, is that the lead confirms they can fulfil the client’s requests before defining requirements and appointing their subcontractors, while I think it would be more advisable to do it the other way around. First you check with your people, and then you confirm to the client.
Is this how you do it?
Anyway, so far it’s exactly the same for the other stages. And it stays the same for a while.
- during the mobilisation stage, the lead does the usual: technology (5.7.1), testing (5.7.2), resources (5.7.3);
- each information provider should apply 5.5.4 during the selection of its lead information provider, collaborate with its lead information provider in applying 5.6.3 prior to confirmation of the appointment, and collaborate with its lead information provider in applying 5.7.1 to 5.7.3 during the mobilisation phase;
- the production stage is pretty standard too: each information provider verifies what they’re starting to work with (5.8.1), works with it in a coordinated way (5.8.2), checks their own information container (5.8.3), and reviews it to approve it (5.8.4) to create information, verify it, and share it with other members of the team;
- the client again can be required by the lead to check information (5.8.5);
- each lead reviews and comments information (5.8.6) whenever the team needs to verify something;
- each lead eventually reviews and authorises information (5.8.7) before submission for acceptance to the client;
- each client reviews and accepts information 5.8.8, and aggregates it into the asset information model (5.8.9): this is specified to happen at the end of short-term work, “but this can also occur during longer-duration work”;
- archiviation (5.9.1) and publication of lessons learned (5.9.2) is performed by the client “after the end of the framework appointments”, but this can happen also during the appointment itself.
Am I crazy or the last two points are the only difference in guidance on how to manage a long-term agreement? While it’s crucial that the asset model is updated during ongoing work, for a long-term agreement, its integration is left as a provision and doesn’t have any effect downstream: I would expect, for instance, that an integration of ongoing work with the asset information model creates new reference material for the ongoing work, and yet it doesn’t seem to be the case.
Also, there’s no mention of situations in which the appointed party might feel they’re unable to feed data into a form that the client can directly federate into the asset information model, and a dedicated example might have been good, to clarify that filling repair dates into a spreadsheet is also compliant with this framework.

5. The Common Data Environment (clause 12)
As you might expect (but you shouldn’t take it for granted), establishing a workflow and selecting the technologies falls upon the client. We’ve been saying that for ages.
5.1. Workflow (clause 12.2)
On the workflow side, the guidance is solid, I must say. Examples of methods and procedures include:
- security protocols for sharing, to make sure people don’t see what they’re not supposed to see or, most importantly, they don’t refrain from sharing when they feel something is too confidential for the general workflow;
- procedures for submission, including the timeframe for reviewing what’s been submitted, and frequency of sharing to ensure collaboration.
The five workflow states are then summarised with a new picture that wants to replace the one we only know too well:
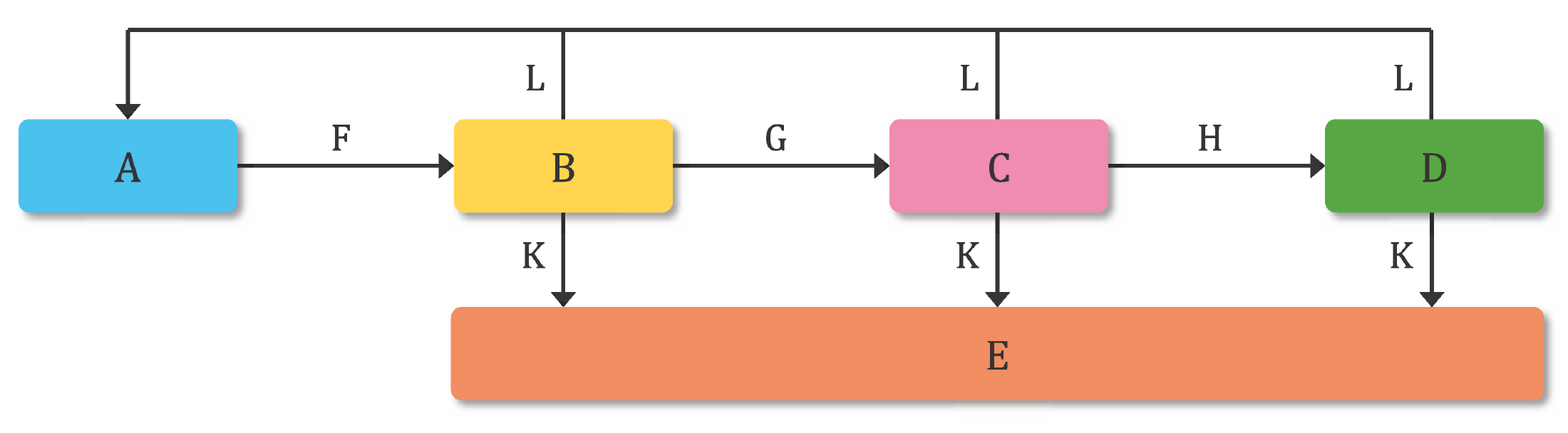
A is the old work-in-progress state, that transitions to a Shared state (B) only through an approval process (F). From the Shared State (B), the information can:
- be rejected or revised (L) and go back to its work-in-progress state (A);
- be superseded or withdrawn (K) and then Archived (E);
- be Authorised (G) to proceed.
From the Shared State (B), information is authorised to proceed (G) into the Submitted State (C), which is a new one if you remember. Again, once submitted, information can be:
- be rejected or revised (L) and go back either to its work-in-progress state (A) or to the Shared State (B) because the drawing isn’t clear on this;
- be superseded or withdrawn (K) and then Archived (E) again;
- be Accepted (H).
Only Accepted information (H) can reach the heavenly Published State (D), but there’s no rest for the wicked: even published information can be rejected or revised (L) and sent back to previous states, while it can also be withdrawn or superseded and sent into archive (E).
These statuses, at least according to clause 12.2.4 of part 3, needs to be assigned to information containers, and there’s a table trying to clarify which party has to assign which purposes for which the information container can be used, and also one to map these stages to the stages described in part 2. The only notable thing is that aggregation of approved information models into the asset information model isn’t part of the approval process but happens only in the published state. Again there’s coordination work that goes beyond reviewing and approving also in the handover stage, and I’m not seeing it.
The most interesting table however is the one trying to determine not only who sees what and who can modify what within the information container (which is normal), but whether properties of the information container can be modified. I’d also like to see something about ownership of data.

Note: there are new states, though they still follow the old “for information”, “for coordination” and “for intended use” scheme.
5.2. Technologies (clause 12.3)
When it comes to the technology, the effort here is to move beyond the CDE as a sharing platform (which was never meant to be) and push towards a better understanding of the Common Data Environment as a coordinated system of enabling technologies, each of them supporting a different portion of the workflow. To clarify this, the guidance creates a distinction between Functional and Non-Functional Requirements, Functional Requirements being features directly connected to the creation, management and use of the information (coordination being a part of the creation, I’m assuming). Non-functional requirements, on the other side, are identified as requirements that aren’t directly connected to what these technologies do, but to how they do it: security, reliability, scalability, conformity to regulations and such. It’s a weird way to put it but my personal programmer understood it, so we’re cool.
There are a few focuses on crucial funtions, particularly the ability to preserve of an unique ID for containers at any level and portability of properties at the information container level, which should be obviously but sadly needs to be said. These properties are specified through tables with codes and meanings, that might be:
- project codes with their descriptions;
- a strategy for encoding revisions;
- workflow states and their descriptions;
- classification codes and descriptions for both information containers, assets and their content;
- codes for sensitivity of information.
It’s all very sensible and, aside from the sensitivity, it’s nothing new.
What’s new is the push towards a higher form of management, through the Information Creation Journal (that’s described more like a log, with “a record of each transition of an information container status for each revision of each information container” including stuff such as the username, the result of the transition activities, and the date and time of the transition).
Also, there’s a focus on the Implementation of an Information Creation Archive, an often neglected status in the previous framework and one that’s going to be crucial for the (many) legal squabbles that will follow this hot mess, I think.
When providing the technologies, though the norm seems to use the term “deploying” that means something else, we are given three options:
- The single provider: everything is provided by the client, though I can see this being interpreted as “everything happens within the same platform”, and it would be the same shit all over again (as if there really is a single solution that allows you to what you need to do);
- The technologies connected to the work-in-progress state are provided by the parties that are producing the information, while the technology connected to everything beyond that is provided by the client;
- Technologies connected with work-in-progress and shared are handled by the providers, while the rest happens with the technologies provided by the client.

There’s also a focus on linking other technologies such as the Enterprise Systems and on the distribution of information containers outside the Common Data Environment (though I would have preferred to see an effort in making these “outsiders” a part of the Common Data Environment in the broader sense.
6. Aggregation of Information Models (clause 13)
As we have seen, the asset information model is only expected to contain information that has been approved, and federation only happens after the work is completed (5.8.9 is the penultimate step in the information production stage, right before project completion). The federation process of project information within the asset model is described, however, as a discretionary work: the model coming out from the project will contain information that’s relevant and not relevant (possibly because it relates to the management or delivery of the project and it will not be useful after completion). “It is pointless to aggregate unnecessary information into the asset information model,” says the norm. “However, there can be practical challenges in separating relevant information for the asset information model from non-relevant information.”
This is a problem I was mentioning a while ago, when I wrote about the difference between the as-built model and the asset information model.
To solve this, the norm offers two ways:
- the 1+N approach: you create separate models, one with all information related to the project stage and another with information that will have to be poured into the asset information model;
- the schedule approach: when defining information requirements, you clearly map out which of them will have to be poured into the asset information model and which ones are only relevant during production.
It’s a granularity approach: one works at the level of the container, while the other goes inside the container and works at the level of systems, objects, single attributes. It would be much easier to understand if we stepped out of this obsession that everything can be a container and made examples using plain language.

To be fair, section 13 tries to step out of this container thing, and defines a model as a collection of containers. I’m not sure that’s helpful.
7. Information Standards, Procedures and Methods (clause 15)
7.1. Standards
The specific approach of the norm is that, since everything will pour into the asset information model eventually, teams should avoid following their own production standards.

I can’t even begin to describe how problematic this statement is. It’s an easy way out, of course. But it creates an incredible management overhead for design and construction managers, who have to re-adapt their workflows and procedures every time a new client enters the picture, not to mention teams that might be working on more than one project simultaneously and have to shuffle between different approaches. And what happens to the infrastructure? All those libraries and components and elements that create a firm’s vocabulary from a technological point of view? According to the norm, you can propose additional standards (on top of, and not replacing the client’s) but they need explicit approval from the client.
And while this might be acceptable from a general perspective, you’d expect part 3 of this kind of norm to design scenarios in a more subtle way.

7.2. Creation Methods and Procedures
When it comes to procedures, apparently you should create one for each thing you might produce. Do you need to create a new model? Procedure. A new wall inside the model? Procedure. Review said model? Procedure.
And while for some of these activities it totally makes sense to create a procedure, we should keep ISO 9001 in mind and create procedures only when a process must be performed in one and just one specific way, either because the risk of leaving it free is too high, or because it’s very complex, or because it involves multiple departments that might not understand each other without a common protocol. The moment we create a procedure for everything, we’ll drown in paperwork.

Other elements are scattered throughout the norm, and I think they’re relevant for the topics of standards: establishing the timeline and the breakdown.
7.3. The Timeline (clause 11)
Timelines are defined through two kinds of schedules in ISO/DIS 19650-2: 2026:
- the information production schedule established during appointment;
- the information production schedule that the lead produces for each appointed party.
Information production, in turn, is the response to a requirement and what’s crucial in this section is that information requirements can describe any kind of thing:
- a large information model with information pertaining to maintenance and operations;
- an information container with other discipline-based containers;
- a document or a drawing;
- a single string of data.
Giving these broad possible sets of products, each information requirement needs to specify:
- the required information (of course);
- the information depth (whatever that means);
- the acceptance criteria;
- supporting information the appointed party will need to consult in order to understand the requirement;
- the delivery date.
There’s no example for this, as far as I can see. There’s only a very ugly picture called “The Line of Sight from Information Purposes to Information Creation” (Picture 6) that tries to explain how you get from the client’s information requirements to eventually explaining to your people what you want to do. I tried to turn it into something comprehensible but I failed. I’ll keep trying.

7.4. The Breakdown Structure (clause 14)
Refreshingly, there’s a specific section on how to compile the breakdown structure for information containers (intended as a collection of models). There’s nothing new here: the breakdown can be:
- asset-based (though the example is a university campus and there’s no explicit guidance on what to do for services that might pertain to multiple assets),
- discipline-based,
- area-based (the example is a highway manager that wants to link every component and portion of the asset to the toll revenues divided by segment, though I think it’s just another way to look at the asset-based approach).
Of course these can be applied at the same time by level, so you might have a first level for the asset type (the villa of a resort), a second level for the asset subtype (specifically villa type B), a third level for the asset instance (the second villa type B of cluster 2), and the element of system in the individual asset (the HVAC system of that specific villa). Using this with naming, the old way, this would be:
V-VB-C2-HVAC
Given the lack of attention to the production stage, there’s no mention of scalability for this, so you’ll have to keep in mind that a breakdown system might be an overkill for a specific stage, while it might become necessariy at a later stage and it’s only normal to proceed in a progressive fashion, just as we do with the development of objects.
There is however another example when you have different design options being carried out simultaneously, with the first level being the option numbered.

8. Information Requirements Depth (clause 16)
The norm aligns with the concept initiated by ISO 7817-1: 2024 (Level of Information Need) and draws the attention on the importance of defining information requirements on the three main levels: geometry, information and documentation.
Nothing new so far.
Again in alignment with ISO 7817-1: 2024, the idea is that each information requirements defines four prerequisites:
- Why (purpose);
- When (milestone);
- Who (actor);
- What (object).
Where isn’t mentioned but of course you also have the need to map where the information will be provided (which container).

9. Transition and Implementation of the Norm Itself
Last, but first in the norm, Part 3 provides input on how to approach the transition from the old framework to the new one. The text proposed two scenarios:
- the progressive: companies and professionals might want to continue using the old framework for ongoing projects (called “information orders”), and use the new standard only for projects either starting on the date of publication or sometimes after the date of publication, because someone will eventually have to read and implement the thing. The idea that this text is ready for direct implementation on each and everyone’s field is laughable.
- the mixed salad: an appointing party (now called “information requester”) might perform information management using some aspects from the old standard and other aspects from the new one, as long as they specify what comes from where through a table in Annex B.
Here’s what I think about Option 2.

According to the norm, you will eventually have to go full-in, but the partial implementation might be in different forms:
- Only for some Assets in an Organisation: magnanimously, the norm understands that a building owner might not be able to deploy people and resources to adopt this approach on all assets of their portfolio, so you might want to do it gradually. Well, thank you for that. Though it would take very little effort, the approach in this description is so clearly owner-focused it makes you want to scream.
- Only for some Organisations in a Project: though the text recognises that you’re in a pickle if some organisations adopt the approach (say, client and designers) and some others don’t (say, the contractors), and even states the information management process will be impaired, it carries on trying to push that “an appointed party can nevertheless still benefit from the information management activities under its control”. Can it though? And what’s the cost of being alone? We own a detailed answer to these questions, and it would have called for a more subtle approach. The best we have is Table 1.
And what does Table 1 do?
Table 1 divides the issue of non-participation between:
- information requester (the former apponting party, to which they probably changed name because people couldn’t understand anyone can be an appointing party if they’re requiring information and to steer away from addressing contractual issues): their non-participation implicates a lack of strategic thinking and of input on information requirements;
- lead appointed party: their non-participation implicates no coordination or planning;
- appointed party: their non-participation implicates no one is actually producing the information.

What I would have appreciated, of course, is a different approach that’s stage-based. What happens to the construction stage when the client doesn’t require information in a structured way? What happens to operations when the contractor refuses to provide an information-rich as-built? After more than 10 years of BIM, I think we deserve a little more depth, don’t we?
10. Conclusions and Recommendations
This draft is a norm that attempts breadth while sacrificing depth, creates administrative overhead without solving coordination challenges, and remains fundamentally owner-centric rather than process-centric.
I think we have five critical failures to address:
- the attempt at universality, present in part 1 and 2, was supposed to be solved in this part: it’s not;
- coordination is the forgotten discipline;
- there’s no attention to guiding the market towards maturity, as if everybody’s already up to speed with their own, well-established asset information model;
- standards and procedures, instead of being aligned with solid frameworks such as ISO 9001, are a death spiral;
- aggregation is oversimplified.
Let’s see what I mean.
10.1. Guidance that applies everywhere applies nowhere.
Specifically, scalability parameters (timeframe, cost, complexity, team size) are thrown together without interaction logic, and there’s no gradation between “you and your cousin changing lightbulbs” and “100-team, 50-year railway concession.” It abandons the middle ground entirely, especially during the design and construction stages. This is a norm written by and for edge cases (very small, trying to prove the point that it applies even for trivial maintenance operations, or very large), leaving 80% of real-world projects unsupported. This means that teams are forced to either over-engineer trivial projects or under-structure complex ones, simply because there’s no proportional framework.
10.2. The Coordination Black Hole
“Coordination” is mentioned repeatedly but never defined, operationalised, or given structural responsibility. There’s checking, yes, there’s approving, and reviewing, but where’s the most crucial work in all information management?
Large projects must accept leadership instability (people will change) with only advice to add “succession planning”: no framework for how coordination survives personnel changes. Design-Bid-Build explicitly separation between design and construction leads with zero guidance on how they coordinate at handover. Multiple concurrent leads are allowed with no mechanism for resolving conflicts or clarifying authority.
This happens because, particularly in multi-lead scenarios, the norm assumes the client is the leader of leaders, but clients typically appoint leads because they can’t lead directly.
If coordination was Part 2’s weak spot, Part 3 institutionalises ambiguity. A norm about information management should have a section on information synchronisation during the ongoing work, leadership transitions and handovers.
10.3. A maturity misunderstanding
The drafters of this norm seem to come from a planet I would like to visit, because this is a planet where every project has an asset information model to begin with, organisational requirements, and a client that knows what they’re doing. Even if the original norm stated the necessity of having Organisational Information Requirements before kicking off a “BIM project”, we all know what happens. Or, at least, I thought we all knew.
Instead of recognising the situation and, for instance, providing guidance on how to extract organisational requirements from a pilot project (as it might happen on Planet Earth), the norm takes everything for granted.
When this isn’t real, section 8.1 encourages scenarios without formal agreements by proposing a third-party mediator model. This encodes dependence on consultants rather than solving structural problems, it normalises avoidance of contractual clarity (which exists for legal protection, not bureaucracy), and pushes toward an even more fragmented, opaque ecosystem.
The norm exists to create structured information management, yet it legitimises structureless relationships and outsources the coordination to a hired third party. This is backwards.
10.4. The Standards & Procedures Death Spiral
The norm states firms should avoid their own production standards and adapt to each client’s standards every time. On top of that, it seems to push for everything to be documented through a procedure. By reading this, it seems to me that a firm’s vocabulary and infrastructure are treated as obstacles to the client’s final glory, instead of assets.
This creates massive overhead for multi-project teams juggling different client standards simultaneously. It assumes firms should be blank slates for every engagement, destroying institutional knowledge that isn’t even being created because the only one maintaining lessons learned is the appointing party. After 10+ years of BIM maturity, this advice is regressive.
The real cost? Small and mid-sized practices, which lack the resources to maintain separate workflows per client, will either non-comply and hide their own processes, over-resource compliance checking or exit the market. Large practices with their own well-established standards will simply not comply because they have the power to do so. This is anti-competitive and reduces standardisation.
10.5. The Aggregation Problem: when does the Asset Model get fed?
The asset information model only receives approved information after project completion (5.8.9), except for long-term agreements when integration might happen at the end of “short-term work” or “can also occur during longer-duration work,” in a manner that’s vague to say the least.
Regardless of when this happens, there’s no feedback loop in place: once the as-built integrates into the asset model, there’s no mechanism for that integrated model to become reference material for ongoing work that might be taking place. In maintenance/operations frameworks, this is the core workflow: ongoing work should reference the integrated asset model continuously.
11. Gaps to be addressed
Off the top of my head, these are the gaps that need to be urgently addressed for the norm to be useful.
11.1: Design-Bid-Build Handover
The norm separates design and construction leads but provides:
- no timeline for when design documentation becomes reference material for construction;
- no mechanism for design lead to participate as an advisor in construction lead appointment (even though this is standard practice);
- no conflict resolution process if (when?) construction discovers design errors or unfeasibility.
Table 1 acknowledges this creates impairment but offers no mitigation.
11.2: Multi-Lead Conflict Resolution
Multiple concurrent leads with no defined:
- authority hierarchy or dispute mechanism, thus overloading the client with an arbiter position they might be unprepared to undertake;
- responsibility for inter-discipline coordination;
- communication protocol during production;
- clear roles: who chairs BIM meetings? Who owns the master model?
11.3: Capability Assessment Timing
Appointed parties are asked to confirm they can meet requirements (5.6.1) before they’ve assessed their suppliers’ (5.5.4) capability, in every agreement framework provided: how is this possible?
11.4: Long-Term Agreement Integration
For maintenance, the asset model should be continuously updated and continuously referenced. The current guidance makes this optional for large project but there’s no example, for instance, of how a repair crew’s data integrates into a facilities management system.
11.5: Partial Adoption (Pragmatic)
Table 1 lists what breaks when different parties don’t adopt the framework, but it doesn’t say what the minimum viable adoption is for each stage. A contractor should know: “If I adopt this but the designer doesn’t, here’s what I must do at handover”.







No Comments