
Nella nostra terza giornata tematica del MasterKeen 6, abbiamo deciso di addentrarci davvero in acque perigliose e, raccogliendo l’interesse di parte della classe, abbiamo sfiorato la superficie di quello che, almeno secondo Forbes, è stato un settore particolarmente significativo nel 2018. La buona notizia è che per imparare qualcosa di machine learning non è necessario vestirsi da Robocop, nonostante il nome possa suggerire altrimenti.
Abbiamo iniziato la giornata con una ricca sequenza di presentazioni raccolte sotto il titolo “La dittatura dell’algoritmo”, ovvero:
- Francesco Cuomo ha inquadrato l’argomento, parlandoci proprio di algoritmi a partire da Computation Works: The Building of Algorithmic Thought e dalla sua lettura personale di La dittatura del calcolo di Paolo Zellini;
- Marcello Imperore dopo aver visto The Imitation Game, ci ha parlato di computer rivoluzionari e sistemi di calcolo con “The Computational Game”;
- Grazia Marotti, che dopo aver visto Bombshell ci ha parlato dell’innovazione tecnologica attraverso la figura di Hedy Lamarr;
- Luigi Gentile ci ha parlato di innovazione tecnologica dopo aver letto L’estinzione dei Tecnosauri, con la sua presentazione dall’ironico titolo “Vita e morte di un connesso viaggiatore”;
- Valentina Betti e Giulia Minini, entrambe reduci dalla lettura di Homo Deus, sono entrate poi nel merito di innovazione tecnologica e machine learning, con il loro “Elementare Watson??”.
Il contributo di Valentina Betti e Giulia Minini
“La rilevante questione teorica e pratica se
la crescita di potenza del computer, la dimensione e la complessità dell’informazione
possano finire per assumere di per sé un significato autonomo,
in assenza di un essere che le interpreti,
non potrebbe forse concludersi in un totale abdicazione?”
Paolo Zellini, La dittatura del calcolo
Intelligenza Artificiale e Machine Learning
1. Un po’ di basi: di che cosa stiamo parlando?
Quello cui normalmente si pensa quando si parla di machine learning è un’area specifica di applicazione, ovvero il cosiddetto Unsupervised Learning: viene utilizzato per analizzare dati non strutturati e non etichettati e si basa sulla capacità del sistema di analizzare cosa hanno in comune i set di dati e di reagire in presenza o in assenza di questi elementi comuni.
I più classici esempi di dati non strutturati sono:
- documenti e file di testo: nel nostro caso si può trattare di documenti di specifiche in assenza di database, BIM execution plan, ma anche capitolati e relazioni illustrative di progetto (un processo del genere è stato tentato durante la redazione della norma Uni);
- siti web, log delle applicazioni, journal: report di esportazione IFC, report clash di navisworks, ma sono i journal di Revit a costituire la più succosa fonte di informazioni su cui provare un po’ di algoritmi e alcuni esempi, più avanti, faranno riferimento proprio a questo;
- dati ricavati dai sensori, il sogno di quella che viene chiamata Smart City: oggi in edilizia la maggior parte dei sensori, quando viene utilizzata, trova impiego nelle infrastrutture o nella fase di cantiere;
- immagini: foto da satellite, rilievi fotografici;
- video: riprese da drone, materiale d’archivio storico, riprese da circuito chiuso in cantiere;
- audio: registrazioni di riunioni o sessioni didattiche;
- comunicazioni via e-mail;
- dati ricavati dai social media.

Varie possibili fonti di dati non strutturati.
Nell’epoca perigliosa in cui viviamo, è sempre bene prendersi un istante per ricordare che non tutte queste categorie di dati sono a disposizione e/o utilizzabili: no, non è legale registrare una lezione o una riunione senza il consenso dei partecipanti (o meglio, lo è per “uso personale”), così come non è legale che l’azienda legga le vostre e-mail o utilizzi ciò che vede sui social media.
Se volete un esempio pratico, provate questo sito, che usa un algoritmo per colorare automaticamente immagini in bianco e nero. Questo è possibile solo avendo a disposizione una vasta banca dati di immagini in cui vengono riconosciute le somiglianze con la vostra immagine. L’unico modo in cui un computer può riconoscere una mucca, e sapere di conseguenza come colorarla, è aver visto molte altre immagini di mucche. L’algoritmo a del sito dire il vero non funziona benissimo, al momento: si limita a dare una patina vintage color seppia più o meno a tutto ciò che non sia una mucca. Se provate ad esempio con un’illustrazione in bianco e nero di Spiderman, questo è quello che ottenete:

Meglio di niente, ma non quello che mi aspettavo.
Ma probabilmente è perché l’algoritmo è confuso tra i vari costumi e le varie versioni di Spiderman che affollano la continuity Marvel.
E, onestamente, non è l’unico.

Fermi tutti, chi diavolo è quella in basso a destra?
Ma seriamente, perché un algoritmo dovrebbe essere più bravo con le mucche e meno con i costumi dell’uomo ragno?
Ci arriviamo tra un attimo.
Il tipo di machine learning descritto fino ad ora, l’unsupervised learning, non è che uno di tre tipologie:
- Unsupervised, appunto, in cui vengono forniti degli input ed è compito del modello individuare una struttura all’interno degli input, identificare gli output significativi;
- Supervised, in cui al modello vengono forniti degli esempi con evidenziati sia i possibili input che i rispettivi possibili output desiderati;
- Reinforcement, in cui il modello interagisce con le variabili e gli agenti di un ambiente mutevole, con l’obiettivo di raggiungere un certo livello di performance in una certa attività.
2. Obiettivi del machine learning
Potremmo suddividere gli algoritmi utilizzati sulla base della tipologia di machine learning che supportano, ma personalmente preferisco suddividerli sulla base del loro obiettivo.
Anche se può sembrare riduttivo, gli obiettivi cui trovano principalmente applicazione sia l’unsupervised che il supervised learning (sul reinforcement possiamo fare un discorso più avanti) sono:
- la classificazione, ovvero la capacità del sistema di individuare autonomamente la posizione di un elemento all’interno di un sistema di classificazione basandosi sull’osservazione delle caratteristiche di questo elemento;
- l’analisi della regressione, ovvero la capacità del sistema di individuare autonomamente delle possibili relazioni tra una variabile dipendente e una o più variabili indipendenti;
- il rilevamento delle anomalie, in cui si cerca di individuare gruppi di dati che si discostano dal comportamento degli altri.

2.1 Classificazione
L’esempio classico che viene fatto per spiegare cosa sia un algoritmo di classificazione, dato che i programmatori amano i gattini, è questo: un algoritmo in grado di riconoscere un gattino da un MG 42. Il che naturalmente porta a domandarci:
- perché mai dovrebbe essere utile per noi;
- perché mai dovrebbe essere utile in generale.
Per rispondere prima alla seconda domanda, l’algoritmo viene utilizzato ad esempio per riconoscere e auto-moderare le immagini inappropriate sui social network, ma anche per filtrare fuori da un set di rilievo le classiche foto scattate inavvertitamente dalla tasca.

In questo paper, la classificazione delle caratteristiche è alla base dell’algoritmo di riconoscimento facciale.
Nel nostro caso, abbiamo diversi campi di applicazione e meriterebbero un paper a parte ma ne elencherò solo tre, ai quattro livelli aziendali: i tre che generalmente individuiamo nella “piramide del BIM” e il quarto individuato dal capitolo 7 della norma UNI 11337.
- da BIM manager: classificazione dei progettisti. Gli strumenti che abbiamo per suddividere i professionisti in gruppi sono limitati e antiquati: normalmente ci si basa su formazione universitaria e inquadramento aziendale. Il primo parametro suddivide i professioisti sulla base di qualcosa che hanno fatto, nella migliore delle ipotesi, dieci anni fa e in un periodo molto stupido della loro vita. Il secondo parametro è auto-avverante perché classifica le persone sulla base della classificazione che è già stata fatta.
La suddivisione in gruppi normalmente serve a diversi scopi in teoria nobili: organizzare le sessioni di formazione e bilanciare i team sono solo le prime due che saltano alla mente. Altri scopi, non necessariamente altrettanto nobili, possono essere individuare le prossime promozioni o organizzare i bonus di produzione. Dico meno nobili semplicemente per l’impatto negativo che l’introduzione di questi sistemi di controllo solitamente porta all’organico.
Gli algoritmi di classificazione, soprattutto in apprendimento non supervisionato, consentono l’emergere di categorie nuove cui non era possibile pensare prima: le cosiddette “cinture” in ambiente Lean Six Sigma, ad esempio, possono essere selezionate con più efficacia.

Buona parte dell’efficacia del metodo Lean Six Sigma si basa sulla corretta individuazione dei suoi campioni. Immagine tratta da qui.
- da BIM coordinator: classificazione dei progetti. Quando partiamo con un nuovo progetto, generalmente ci affidiamo all’esperienza per valutare di quante persone e di quanto tempo avremo bisogno per portarlo a termine. Abbiamo pochi strumenti di classificazione se non la disciplina (progetto di architettura, di interior, strutturale, impiantistico), la tipologia (residenziale, alberghiero, ospedaliero, ecc.) e qualche flag trasversale (intervento in contesto storico, riconversione, ecc.), ma se potessimo addestrare un sistema a considerare tutte le variabili potremmo stilare una graduatoria di progetti che va dal “business as usual” (progetti che il nostro organico può realizzare bendato e con una mano dietro la schiena) fino a progetti che presentano un alto fattore di rischio. Non dimentichiamo che individuare i fattori di rischio in modo efficace è un requisito per lavorare in qualità.
- da CDE manager: classificazione dei documenti. Il miglior strumento che abbiamo a disposizione nella classificazione dei documenti, al momento, è una nomenclatura ben fatta: un sistema che ha compiuto vent’anni l’anno scorso e che si basa fondamentalmente su un input umano: posso nominare le lettere d’amore della mia ex fingendo che siano una relazione tecnica e il sistema le caricherebbe tranquillamente, senza troppe obiezioni. Sistemi più evoluti consentono di cross-referenziare alcuni codici con la tipologia di file che ci si attende e che viene consentita nel BIM Execution Plan, ma poco di più. Il sistema potrebbe essere addestrato a classificare i documenti in modo più flessibile e trasversale, basandosi su metadati non associati manualmente ma estratti dai contenuti dei documenti stessi: in questo modo un CDE potrebbe quantomeno proporre una codifica automatica sulla base di ciò che già vede all’interno del documento, anziché affidarsi al data entry manuale.
- da BIM specialist: classificazione delle clash. Ricordate l’annosa questione riguardante il grado di “serietà” di una clash? Non parlo della sua tipologia (hard, soft, time), ma del suo corrispettivo livello di allerta. È stato uno dei miei primi articoli sul BIM, nel cenozoico scorso. Un sistema potrebbe teoricamente essere addestrato, sulla base di una serie di esempi in cui alle clash era stato correttamente associata l’azione corrispondente e organizzare le clash nel report (anche) sulla base della loro priorità. In questa direzione va il tentativo del prodotto ClashMEP, sviluppato da BuildingSP: un sistema di rilevamento clash in tempo reale all’interno di Revit. Il suo funzionamento è spiegato da Brett Young in questo articolo.

2.2 Regressione
La regressione cerca di risalire alle variabili che causano certe configurazioni all’interno dei dati forniti. In altre parole, la regressione è utile ogni volta che siamo nella posizione di doverci o volerci domandare perché qualcosa accade nel modo in cui accade, oppure vogliamo ricavare dei dati che non abbiamo a partire da fenomeni che invece possiamo osservare.
Esistono vari tipi di regressione, ma la più semplice da comprendere è la regressione lineare cerca di stabilire una relazione lineare tra una o più variabili, siano esse dipendenti o indipendenti. Quando le variabili sono dipendenti, spesso l’operazione è semplice e, in questa sua forma, l’analisi statistica ne fa uso da anni in strategie di project management come il già citato six sigma. Quando sono indipendenti, i risultati possono essere inaspettati. Possiamo ad esempio individuare una correlazione tra il capoprogetto e i ritardi all’interno di una commessa. Anche in questo caso, un paio di applicazioni potrebbero essere:
- da BIM coordinator: individuazione della correlazione tra una modifica e le aree del modello impattate. Nella gestione di un progetto complesso, le modifiche in corso d’opera sono inevitabili. Spesso però, specialmente quando le richieste di variante sopraggiungono in fasi molto avanzate, diventa difficile prevedere l’impatto sul resto del modello. Oggi per questa previsione ci si affida all’esperienza del BIM coordinator, ed è per questo che il ruolo non può essere ricoperto da un ragazzino appena uscito da un master o da una risorsa che fino a pochi mesi prima era in posizione di stage.
Senza nulla togliere a questa affermazone, immaginate un sistema che sia in grado di analizzare l’impatto delle modifiche sullo storico di modelli passati ed a prevedere quindi l’impatto di una modifica in corso sulle altre parti del modello.
Ho incontrato un progetto del genere all’Autodesk University di Londra, l’anno scorso: si chiama KADlytics ed è focalizzato sulla progettazione meccanica, ma immaginate uno strumento del genere per un modello o una rete di modelli complessa.

KadLytics: confronto tra la rete di relazioni così come impostate e così come viste dall’Intelligenza Artificiale. Io ci vedo un cammello con le ali.
- da CDE manager: previsione del carico per i pacchetti di consegna. Uno dei colli di bottiglia più significativi, lavorando al Level 2, è il caricamento sul CDE (BIM360 permettendo: il prodotto è diventato veramente buono e mi ripropongo di parlarne a breve). Sia che si tratti di caricare solo modelli, sia che si tratti di caricare e rinominare una grande quantità di modelli, tavol e documenti, si tratta di un lavoro la cui durata è difficilmente pianificabile, anche quando abbiamo una document list chiara ed esaustiva degli elementi presenti nel pacchetto di consena (e sappiamo quanto spesso questo succede). Sarebbe teoricamente possibile addestrare un algoritmo per prevedere l’entità di questo lavoro in anticipo, sulla base della fase e della tipologia di progetto.
2.3 Rilevamento delle anomalie
Ipotizziamo, come al solito, di avere il modello di un albergo che sta subendo profonde e continue revisioni. Il layout di ogni stanza deve rispettare delle regole che non sono completamente quantitative o che sono combinate in troppe variabili perché sia ragionevole programmare un normale script di model checking (se ricordate, si era fatto un esperimento di programmazione adattiva per layout di camere d’albergo all’Autodesk University del pleistocene scorso, ma si trattava del solo bagno in un layout molto semplice). In più, specie se siamo in edificio storico, ogni stanza è diversa. Piccole differenze, magari, che l’occhio umano individua facilmente come rilevanti o meno, ma per un computer ogni differenza è significativa.
Un algoritmo di rilevamento delle anomalie lavora esattamente come lavorerebbe l’occhio umano: individua le differenze e, sulla base del materiale di riferimento e del continuo apprendimento, decide se sono significative o meno. Viene utilizzato, ad esempio, per una più efficiente segnalazione dei problemi. Niente più ticket aperti perché l’operatore non ha controllato di aver attaccato la corrente. O, per lo meno, quello è l’obiettivo di questa architettura Azure.

3. Bias
Che si tratti di supervised o unsupervised, il machine learning fa uso di architetture e algoritmi. Tralasciando l’architettura, che non ci compete, entrare un po’ di più nel merito degli algoritmi ci può aiutare a capire meglio di che cosa stiamo parlando e rilevare altre applicazioni in ambito BIM.
Prima di ciò, però, è necessario sgombrare il campo dal solito equivoco. Da solo, il sistema non fa nulla: nei sistemi di apprendimento supervisionato, le variabili sono selezionate da un essere umano e anche nell’apprendimento non supervisionato abbiamo sempre una collezione di umani dietro alla selezione del materiale da usare come base per l’apprendimento.

Come sempre, l’intelligenza di un algoritmo è pari solo a quella di chi lo usa.
In uno dei nostri esempi precedenti, ipotizziamo di poter estrarre dati dai modelli circa la performance dei progettisti e dobbiamo partire con degli assunti riguardo ai parametri che determinano i gruppi: potremmo per esempio avere il numero di famiglie prodotte e la disciplina di appartenenza: non abbiamo idea di quanti saranno i gruppi risultanti, ma abbiamo comunque determinato che i parametri sono determinanti nella suddivisione dei gruppi. I gruppi risultanti saranno probabilmente separati seguento questi valori, perché abbiamo originariamente assunto che fossero importanti.
Potremmo quindi scoprire che gli architetti producono poche famiglie di Revit, assumere che quindi un architetto non abbia bisogno di saper realizzare una famiglia per completare un progetto e non prevedere la costruzione di questo skill nei programmi di training, quindi ovviamente avremo architetti che non producono famiglie (perché non sono capaci): questo è un tipico esempio di bias, di pregiudizio.
Quando si tratta degli umani, i miei bias preferiti sono:
- bias di conferma. Stando allo psicologo americano Burrhus Frederic Skinner, lo stesso di cui parliamo quando parliamo di condizionamento operante, tendiamo ad evitare gruppi di persone che ci fanno sentire a disagio, e siamo messi a disagio da persone che la pensano diversamente come noi: quando questo si verifica, siamo in presenza di una dissonanza cognifiva che provoca appunto un bias di conferma. In altre parole, ci allineiamo alle opinioni che alimentano il nostro punto di vista: se siamo di sinistra leggiamo giornali di sinistra e frequentiamo persone di sinistra (tranquilli, è valido anche per l’altra parte); se siamo convinti che una persona ci odi, vedremo solo i segnali che confermano ciò di cui siamo già convinti.

- Bias di Gruppo. Per chi ha recentemente letto i libri di Yuval Noah Harari, in particolare il primo, dovrebbe essere chiara la forza – e la debolezza – del nostro lato tribale: questo genera un altro bias, il cosiddetto bias di gruppo, in cui tendiamo a sopravvalutare le qualità del nostro gruppo (la nostra squadra vince perché ha bravi giocatori) e ad attribuire i successi degli altri gruppi a fattori che non hanno a che vedere con le qualità dei loro membri (la squadra avversaria ha vinto perché l’arbitro è corrotto).
- la fallacia dello scommettitore (la trovate in giro in alcuni “articoli” come Fallacia di Gabler, come se Gabler fosse un tizio, ma è un banale typo + errore di traduzione) è un errore logico che ci porta a pensare che gli eventi passati abbiano qualche effetto su eventi presenti governati dal caso: il fatto che sia uscita croce per le venticinque volte passate, non aumenta le possibilità che questa volta esca testa (ma solo quelle che la moneta sia truccata).
Se siete curiosi, la magnifica infografica di designhacks.co suddivide 180 bias in quattro quadranti:
- quelli che formiamo quando abbiamo troppe informazioni;
- quelli che formiamo quando non troviamo abbastanza significato in quello che vediamo;
- quelli che formiamo per permetterci di agire (e reagire) in fretta;
- quelli che formiamo per selezionare ciò che ci occorre ricordare.

Applicato al machine learning, il concetto di bias non sottointende un problema etico meno grave. Nel nostro esempio di poco fa, abbiamo impostato il raggruppamento dei dati in gruppi che supportassero un’idea che già avevamo formato, ovvero che la quantità di componenti prodotti sia legata alla disciplina di appartenenza del progettista. Ogni volta che un algoritmo conferma ciò che già stavamo pensando, non stiamo usando il machine learning al suo potenziale: il punto dovrebbe essere consentire all’algoritmo di scoprire pattern diversi da quelli che sapevamo già esistere, qualcosa di inaspettato, che ci insegni qualcosa che non sapevamo e ci apra nuove prospettive.

Dobbiamo consentire all’algoritmo di essere creativo.
Dobbiamo consentire all’algoritmo di insegnarci qualcosa che ancora non sapevamo e questo è possibile solo riducendo il bias. Ma come fare?
Secondo Vince Lynch, che ne ha scritto l’autunno scorso su TechCrunch, gli strumenti sarebbero tre:
- Scegliere un modello di apprendimento adeguato al problema. Se non siamo sicuri della relazione tra vari fattori, ad esempio, un approccio esplorativo di clustering potrebbe rivelarsi più efficace del tentativo diretto di una regressione lineare;
- Scegliere un training set che sia rappresentativo. L’algoritmo non conoscerà niente di diverso da ciò che noi gli consentiamo di conoscere e, sulla base di quel campione, trarrà delle considerazioni che potrà applicare a un campione più vasto: se forniamo all’algoritmo un training set relativo solo a progetti di strutture, non possiamo aspettarci che il suo lavoro sia applicabile anche a progetti di altre discipline;
- Tenere sotto controllo le prestazioni del sistema confrontandole con dati reali. Il più delle volte, l’operato di un algoritmo è verificabile confrontandolo con controlli a campione sulla realtà o, nel peggiore del casi, verificando a posteriori l’efficacia delle sue predizioni. L’unica cosa peggiore di un oracolo che non indovina e un oracolo abbastanza potente da riconfigurare la percezione della realtà (anche in questo caso, leggere Yuval Noah Harari è fondamentale).

Scegliere il modello di apprendimento adeguato è sempre cruciale, per le intelligenze artificiali come per gli umani.
4. Algoritmi e applicazioni
Nella maggior parte dei casi, abbiamo la fortuna di lavorare con dati strutturati: in fin dei conti il nostro modello BIM è un database e le cose devono essere andate veramente storte per trovarci in presenza di un numero significativo di quei dati che vi ho elencato come esempio di dati non strutturati. Questo significa che possiamo fare qualche esperimento di supervised learning, ed è una fortuna perché ritengo che sia significativamente più semplice da capire, anche se forse meno affascinante.
4.1 Recuperare i dati
Per recuperare i nostri dati, abbiamo diverse possibilità:la via più rapida è quella di ricorrere ai journal di Revit o ai report delle clash di Navisworks. Ovviamente, come si diceva poco sopra, questo ha veramente poco senso se non avete un set di dati significativo, ovvero joural/report di molti progetti simili a quelli sui quali volete che l’algoritmo operi. Questo è sicuramente lo scoglio più difficile da superare. Fortunatamente, per quanto mi riguarda, non è l’età ma è il chilometraggio (ok, comincia a essere anche l’età): è un problema che non ho. Se voi l’avete, non posso risolverlo: tornate qui quando avrete una base dati adeguata.
Un problema che invece posso risolvere è se non sapete come accedere ai journal di Revit o come leggerli. In particolare, ne ho parlato qui. Potete anche usare Dynamo, un plug-in, le scimmie volanti, l’importante è che alla fine dell’operazone abbiate una collezione significativa di dati significativi su cui lavorare.

Vanno bene anche queste.
4.2 Provare ad abbattere il bias
Avendo questi dati a disposizione, il modo migliore per provare ad eliminare il bias è provare a far parlare i dati. Se usate Seaborn, ci sono un paio di funzioni che considero particolarmente efficace.
La prima è l’utilizzo del pairplot, una funzione di Seaborn che consente di restituire la visualizzazione a coppie di tutti i parametri utilizzati nell’algoritmo, in modo da poter iniziare a vedere se si sono creati gruppi o pattern significativi nei grafici a dispersione. L’esempio riportato nei materiali di supporto di Seaborn mostra alcune possibili restituzioni nella correlazione tra le dimensioni dei petali e dei sepali in un fiore. Per i non botanici, i sepali sono quelle foglioline alla base della corolla di un fiore che, a seconda delle circostanze, possono anche far parte della corolla stessa.

Nella base dati utilizzata dall’esempio, scopriamo che esistono due categorie di fiori: quelli con i petali al di sotto di una certa lunghezza hanno una lunghezza del sepalo che non supera mai un certo valore, mentre al di sopra di una certa lunghezza del petalo tende a esserci una correlazione proporzionale tra questo valore e la lunghezza del sepalo. La stessa conclusione sembra potersi trarre prendendo la larghezza del sepalo, anziché la lunghezza, mentre non sembra esserci alcuna correlazione tra le due dimensioni del sepalo stesso. E’ una scoperta interessante? Non ne ho idea, non sono un botanico.

Un’altra operazione interessante che ci viene consentita da questo metodo è individuare gli elementi isolati, che non appartengono a nessun cluster. Maggiore è la distanza dell’elemento da tutti gli altri, maggiore l’anomalia è interessante.

…e tu cosa ci fai lì, solo soletto?
Analizzando l’anomalia potremmo scoprire che:
- è riconducibile a una disomogeneità della base dati fornita (es: è l’unico fiore di una certa famiglia);
- effettivamente è il punto di partenza per nuove riflessioni che non erano mai balzate all’occhio.
Questo è naturalmente valido anche nel nostro esempio di tanto tempo fa: ipotizzando di avere dati relativi ai progettisti, potremmo scoprire un professionista isolato rispetto a particolari skill comuni alla sua categoria, o una categoria che riporta particolari comportamenti.
Un’altra funzione molto interessante è la creazione di una heatmap.
La heatmap consente di visualizzare i pattern nel set di dati, e quindi di interpretarli parzialmente in un modo che sia di aiuto e di indirizzo all’algoritmo. Nell’esempio fornito da Seaborn, ad esempio, possiamo vedere che la gente ha sempre volato di preferenza in estate, e sempre di più in modo più o meno regolare fino al picco che – all’interno del set di dati fornito – corrisponde al 1960.
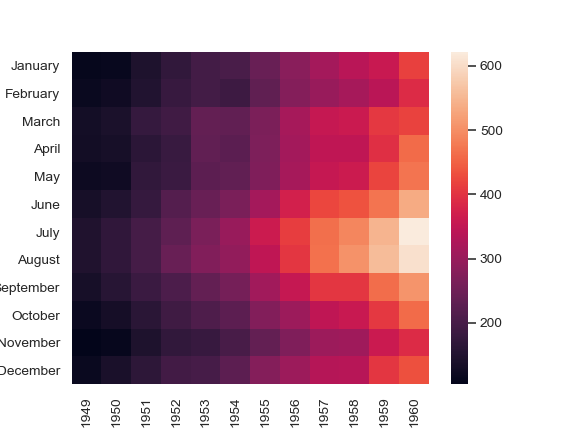
In questo caso, la legenda colori è impostata in modo da avere un colore più chiaro sul valore massimo e più scuro sui valori minimi.
Ho visto una prima applicazione di analisi dati a Saint Louis, questo agosto, nello splendido laboratorio di Nick Kovach dall’incoraggiante titolo Machine Learning, It’s not just for Data Scientists. Nella sua sessione, utilizzava pacchetti di Anaconda per analizzare dati provenienti dai Journal files di Revit raccolti nel suo studio: facendo delle ipotesi, analizzava i dati a disposizione per verificare la correlazione tra la dimensione dei file e il numero di tavole, o la disciplina e l’uso dei view template. Nel suo laboratorio, Nick usava la funzione Heatmap per individuare un’eventuale corrispondenza tra cinque valori: le viste in tavola, la dimensione del file, i warning, le viste presenti nel file e i livelli.

Scopriva una correlazione molto alta tra le viste e le viste messe in tavola, ovvero la maggior parte delle sue viste erano poi impaginate. Bravo. Non sempre sono stata così fortunata con i file che ho analizzato.
Il significato della heatmap però dovrebbe esservi evidente: più il colore è chiaro, più è probabile che ci sia una correlazione interessante. Nel nostro caso potremmo voler analizzare la correlazione tra le dimensioni del file e il numero delle viste (non così forte come ci si potrebbe aspettare), tra il numero dei warning e le dimensioni del file (ancora più basso, se possibile). Quindi, a una prima occhiata, vediamo che il dataset per l’apprendimento è costituito da file sani e ordinati, con un numero davvero limitato di viste non impaginate.
Senza aver mai visto nemmeno di striscio un file di Nick.
Non male, no?
5. Un riassunto
Riassumendo, alcuni degli algoritmi che abbiamo visto procedono in queste direzioni:
- operando un clustering, ovvero tipologie di algoritmo che sono in grado di raggruppare set di oggetti che vengono ritenuti simili: viene utilizzato nel data mining esplorativo, nell’analisi dati statistica, per l’analisi immagini, e forse la conoscete con il nome di pattern recognition: it walks like a duck, it quacks like a duck, it’s probably a duck.
- consentendo il rilevamento delle anomalie, ovvero tipologie di algoritmo che individuano le ricorrenze nel set di dati ed evidenziano gli elementi che divergono da queste ricorrenze;
- con l’impiego dei cosiddetti neural network, tra cui ad esempio le self-organizing maps;
- adottando gli approcci cosiddetti a variabili latenti, che lavorano a partire da una variabile cosiddetta “manifesta” e ne individuano una correlazione con altre variabili.
Alcuni degli algoritmi utilizzati hanno nomi che potrebbero tranquillamente essere quelli di un trucchetto di D&D, ma dovremmo riuscire a castarli anche senza classe di prestigio:
- Support-Vector Machines, che si usano sia per la classificazione che per l’analisi della regressione: data una serie di esempi marcata come appartenente a una di un set di categorie, il sistema ne analizza le caratteristiche e, dati altri elementi, le ricerca per individuarne l’appartenenza a quelle medesime categorie.
Ad esempio, ipotizziamo di avere una serie di modelli disciplinari (strutture, architettonico, MEP, interni, landscape): un algoritmo funzionante sarebbe ipoteticamente in grado di categorizzare autonomamente un modello di architettura rispetto a un modello d’interior e, se analizzato, di restituirci quali sono le caratteristiche di un modello d’interior. Un’informazione che si rivelerebbe essere piuttosto preziosa per i programmi di training aziendali. - Decision Trees, anch’essi usati sia per entrambe le nostre applicazioni: si utilizzano per prevedere il valore di una variabile dato l’input di una serie di altre variabili da essa indipendenti.
Ad esempio, non occorre un algoritmo di machine learning per prevedere le dimensioni di un file assegnando, come input, la quantità di elementi che si prevede saranno contenuti nel file stesso, ma questo tipo di informazioni non è generalmente disponibile. Avendo però a disposizione una serie sufficientemente nutrita di esempi da dare in pasto all’algoritmo, è possibile prevedere le dimensioni che un file arriverà a raggiungere dando come input le informazioni tipicamente disponibili all’inizio di un progetto, ovvero la sua tipologia e le sue estensioni generali. Il risultato, come si può facilmente immaginare, è prezioso nella definizione delle strategie di breakdown del modello e dovrebbe servire ad impedire l’insorgere di piccoli imprevisti come l’ulteriore necessità di suddividere il modello in fasi avanzate della documentazione. La combinazione di più decision tree è chiamata Random Forest. - K-Nearest-Neighbor, sono algoritmi di pattern-recognition il cui risultato varia se sono utilizzati per la classificazione o per la regressione. In entrambi i casi, l’algoritmo posiziona l’oggetto fornito all’interno di uno spazio, ponendolo in prossimità di quelli che ritiene simili: nel caso della classificazione, ogni
5.1 Clustering
Spendiamo altre due parole sul clustering, che è probabilmente il più semplice da comprendere. Ipotizziamo di avere un corposo set di dati relativo al lavoro svolto in un certo periodo di tempo dai progettisti che usano Revit all’interno del nostro studio. Un algoritmo di clustering, prende l’insieme degli oggetti osservati e li suddivide in gruppi creati a seconda delle loro somiglianze.
Per visualizzare il tutto, abbiamo ovviamente bisogno di un grafico di dispersione e un grafico di dispersione ha bisogno di sapere quali valori inserire sugli assi. Data la limitatezza della nostra strumentazione (sia tecnologica che mentale) possiamo avere solo due, al massimo tre assi: questo significa che dobbiamo prendere delle decisioni e chiedere al computer di organizzarci i cluster secondo alcuni valori piuttosto che altri.

“So You Have Some Clusters, Now What?” di Fan Zhang e Inna Kaler su Medium è un articolo che spiega in modo estremamente chiaro la correlazione tra clustering e bias.
Il punto è: cosa rappresentano questi cluster?
Ormai dovremmo sapere come capirlo.
Il clustering può essere usato per individuare regressioni e classificazioni. Nel’esempio sottostante, ad esempio, un algoritmo di Azure realizza una regressione logistica a due classi (che nonostante si chiami “regressione” è in realtà un algoritmo di classificazione, perché Microsoft ci vuole malissimo).

Se ancora non vi è chiaro, guardate questo altro esempio in cui, sulla base di un clustering, un altro algoritmo di Azure scopre che partecipano al Burning Man persone tra trenta e quarant’anni con diversi livelli di reddito ma tendenzialmente superiore ai 60.000 $ l’anno. Mi sarebbe piaciuto avere l’anomalia di un ricchissimo vecchietto, da qualche parte, ma purtroppo l’algoritmo non lascia spazio ai sogni. Da questo cluster, viene estratto un albero decisionale, una sorta di diagramma di flusso in cui è possibile restringere le probabilità di partecipazione dell’intervistato al Burning Man.

Se guadagni troppo poco o sei troppo piccolo, ciccia.
6. Reinforcement Learning
Pensavate che me ne fossi dimenticata?
Il terzo tipo di machine learning comunemente indivudato è il Reinforcement Learning, che si occupa di lavorare sul miglioramento nelle strategie decisionali degli agenti all’interno di un ambiente chiuso. La tipica applicazione di quest’area è quella delle intelligenze artificiali nei videogiochi e, nella sua forma più semplice, gli algoritmi di reinforcement learning sono processi decisonali di Markov, ovvero modelli in cui a ogni agente viene associato uno stato corrente e delle azioni possibili che conducono ciascuno a uno stato differente. Le decisioni vengono prese sulla base di una funzione di utilità che determina se il nuovo stato sarà migliore o peggiore dell’attuale, sulla base di una serie di parametri. Un modello di Markov non tiene conto degli stati passati dell’agente e, quindi, non ha memoria. La maggior parte degli algoritmi di reinforcement learning si misura con il problema dell’esplorazione e della definizione di efficienza per ogni possibile stato. Il celebre DeepMind di Google usa l’applicazione di un algoritmo per il reinforcement learning, detto Q-learning, applicato al Deep Learning.

Lo Shogi gli è piaciuto molto di più del Go e degli scacchi, è evidente.
Questo tipo di algoritmi è quello alla base delle intelligenze artificiali che potrebbero guidare autonomamente le nostre auto ma, in attesa di un’intelligenza artificiale che possa coordinare autonomamente i nostri modelli, la cosa non ci riguarda direttamente.
7. Bibliografia essenziale
Per chi volesse approfondire l’argomento, consiglio la lettura di:
- Jerry Kaplan, Humans Need Not Apply: A Guide to Wealth and Work in the Age of Artificial Intelligence.
- Nick Polson e James Scott, AIQ: How People and Machines Are Smarter Together;
- Sean Gerrish e Kevin Scott, How Smart Machines Think.
.

 .
.
E, naturalmente, i testi da cui siamo partiti:
- Yuval Noah Harari, Homo Deus: A Brief History of Tomorrow;
- Yuval Noah Harari, 21 Lessons for the 21st Century.








2 Comments
Pingback:ISO 19650: che cosa è cambiato? (1) | Shelidon
Posted at 00:05h, 24 February[…] 1 fa uso principalmente di dati sia strutturati che non strutturati (per la differenza rimando al focus sul machine learning di qualche settimana fa) mentre nella fase 2 introduce il concetto di modello informativo federato: […]
Pingback:I asked ChatGPT to answer some questions on Yoruba history. It did not go well – Shelidon
Posted at 09:42h, 23 April[…] tools are becoming mainstream. I’ve been teaching students about this stuff for a while (see here, for instance), and I cringe at some stuff that is being said these days, both in favour and […]