
I already spoke about the value of failing fast on projects; it’s not anything I invented, and yet our mindset always shifts towards trying to avoid failure. We try to build bulletproof workflows. We have a failsafe in place for everything. We craft The One Script To Rule Them All. We said that BIM means starting with the end in mind, and we believed it meant that everything needs to mapped, trialed and tested. If you’re familiar with ISO 19650-2, there’s a whole chapter on the preparation of a project, in which technological solutions are evaluated, environments are tested, meta-models are created and prototypes are built just to stress-test the systems.

Inevitably, there’s a moment in every project when something breaks. A workflow collapses. A brilliant idea unravels under scrutiny. A script that worked yesterday refuses to cooperate. Someone asks for a deliverable that reveals a critical gap in the plan. It’s a moment that feels, in the most literal sense, like the end of the world as we know it. And we don’t feel fine.
This guideline is for those of us who dread that moment; for students venturing into digital design and construction with big ideas and fragile prototypes, for peers navigating the uncertainty of innovation in environments where reliability is king and mistakes are costly, for everyone who has been told to “innovate” without being given permission to fail.
What follows isn’t a manual. It’s not a step-by-step guide to agile management or a summary of project delivery frameworks. It’s a lived reflection—a series of notes collected from the field, drawn from my experience as a digital consultant, workshop facilitator, and collaborator across teams that build, test, break, and rebuild things every day. Trust me, I know what it means to fail. I know what it means to fail early and I know what it means to fail late, when you’ve already invested all of yourself into the fucking project.
Preface: Failing Fast and Antifragility
In my previous reflections on antifragility in digital innovation, I made the case that digital workflows aren’t fragile—they’re iterative by design. They can absorb shocks, reconfigure themselves, and emerge stronger… if we let them. This post continues that line of thought, but from a more personal angle: what it means to work through failure, rather than around it, and why we need to build cultures and mindsets that make this possible.
“Failing forward” isn’t about failing for the sake of it. It’s about failing with purpose, in ways that allow us to learn, correct course, and build better things faster. It’s about embracing the risk that teaches us something before the stakes get too high. It’s about treating early setbacks not as signs of weakness, but as the raw material of eventual strength.
This is what I’ve learned—sometimes the hard way. And this is why, when things fall apart, I pay attention. There’s always something in the wreckage worth rebuilding.

1. Scene One: When It All Falls Apart
1.1 A Personal Story: The Clash That Never Was
It starts like this every time.
We’re early in the design process. Maybe too early, depending on who you ask. I suggest we run a clash detection round. Not a full coordination session—not yet. Just a first pass, to test how the models are aligning.
The reactions are predictable.
“But our model’s not ready.”
“We’re still working on the main piping routes.”
“Surely it’s too soon.”
But it’s not too soon. That’s exactly the point.
Clash detection, in its purest form, isn’t just about finding collisions between walls and ducts. It’s about surfacing design misalignments. And you can’t do that when you have other problems in the way. You know, those small, minor things like discrepancies in coordinate systems, file origins, naming schemes, or level heights that accumulate like technical debt. If left unchecked, they turn every subsequent meeting into a blame game.
I’ve seen what happens when we wait to start with coordination. Models developed in different offices, sometimes even on different continents, come together for the first time too late. Each one is built with its own internal logic, each assuming its own version of “truth.” Even if the BIM execution plan was correctly transmitted to everyone, sometimes they even had a template file with the correct set up, and yet there’s always someone who thought Project North was going to look prettier the other way, someone who considered their origins would work better if shifted, people with their own grids and levels, and there’s always a studio who decided to raise the sea level.

The result? The clash detection report is either empty, because systems can’t see each other, or it lights up with hundreds of so-called “errors”—none of which are meaningful collisions. They’re semantic misfires: grids that don’t line up, levels that don’t match. The data doesn’t know how to talk to itself.
And here’s the real danger: coordination stops before it even starts.
Instead of analysing the report, teams fall into defensive positions. “Our model is correct. The others need to fix theirs.” Meetings devolve into a semantic cold war, where no one is wrong, but everything is broken. What should have been an opportunity to align becomes a bureaucratic stalemate. The clash detection never actually happens.
1.2 The Resistance to Failure and the Shift That Matters
This, I’ve learned, is a resistance not just to technical misalignment, but to the idea of showing your work before it’s finished. It’s the instinct to protect what’s fragile, to delay exposure until the file is polished, safe, unassailable. I understand the impulse. After all, nobody wants their mistakes broadcast across a coordination report. But this is where the mindset has to shift.
If we treat early coordination as an exam, people will always wait to be perfect. If we treat it as a technical test, people will not commit to the process. We need to treat it as diagnostics, as routine as checking the oil before a long trip, then we can start to talk about why your pipes want to go through my walls.
What changes when you normalise “failing early” is precisely the kind of conversation you’re trying to kick-start with the whole clash detection thing. You no longer ask: “Who’s to blame?” You ask: “What needs aligning?” The clash detection becomes what it was always meant to be: not a tribunal, but a coordination starter. Revisions aren’t exams. They’re part of the rhythm. And technical problems are no longer threats—they’re signals that the system is working as it should.
When you build that kind of culture, failure stops being the end of a phase and starts being the engine of progress.
2. Diving Deeper: Why Failure Matters (Especially in Critical Projects)
In my experience, the more critical a project is – the tighter the schedule, the higher the budget, the more eyes watching – the less willing teams are to make room for failure. That’s logical. And yet, that’s a paradox we need to disband.
We know these are the projects that require the most rigorous coordination, the strongest collaboration, the clearest standards. And yet these are the environments where people are most reluctant to admit uncertainty, to expose partial work, or to raise red flags too early. The stakes are too high. Or so it feels.
2.1 The Paradox of Risk-Aversion
In high-stakes settings and for high-end professionals, there’s a tendency to conflate perfectionism with professionalism. We think that if we delay exposing the work until it’s perfect, we’re protecting the project from risk. In fact, we’re doing the opposite. Every unspoken assumption, every unchecked convention, every undocumented deviation from the standard—it all piles up in the shadows. And because no one wants to fail “in public,” errors stay hidden until they’re baked too deeply into the system to be easily resolved.
What begins as a protective instinct becomes a structural vulnerability.
In digital workflows, risk is front-loaded or back-loaded, never eliminated. And the longer you wait, the more expensive it gets. Failure postponed is just failure with compound interest.

2.2 Early Mistakes, Stronger Systems
Digital projects thrive when they’re built for iteration, not preservation. Early mistakes—when surfaced and addressed—don’t just prevent bigger failures later; they actively strengthen the system. Think of it like stress testing.
When a model misaligns with a coordinate system or a naming convention causes a false clash, that’s a stress point. You can patch it, or you can refactor the logic that created the mismatch in the first place. The latter is harder, but it’s how your workflows mature. Over time, this becomes a form of antifragility: your process doesn’t just survive shocks, it adapts. You start building templates that avoid the same pitfalls. You write documentation not to defend your work, but to help others succeed. You design standards that are flexible enough to catch edge cases. In short, you create a system that’s more robust because it has been tested by small, early, survivable failures.
2.3 Emotional Resilience and Team Safety
But there’s another layer, arguably more important than the technical one.
Teams that operate in cultures of fear and defensiveness – where the first error becomes a trial, and feedback feels like judgment – will never raise problems early. They’ll bury them, delay them, work around them until the deadline makes confrontation unavoidable. It’s a concept we explore in connection to DevOps (see here, for instance).
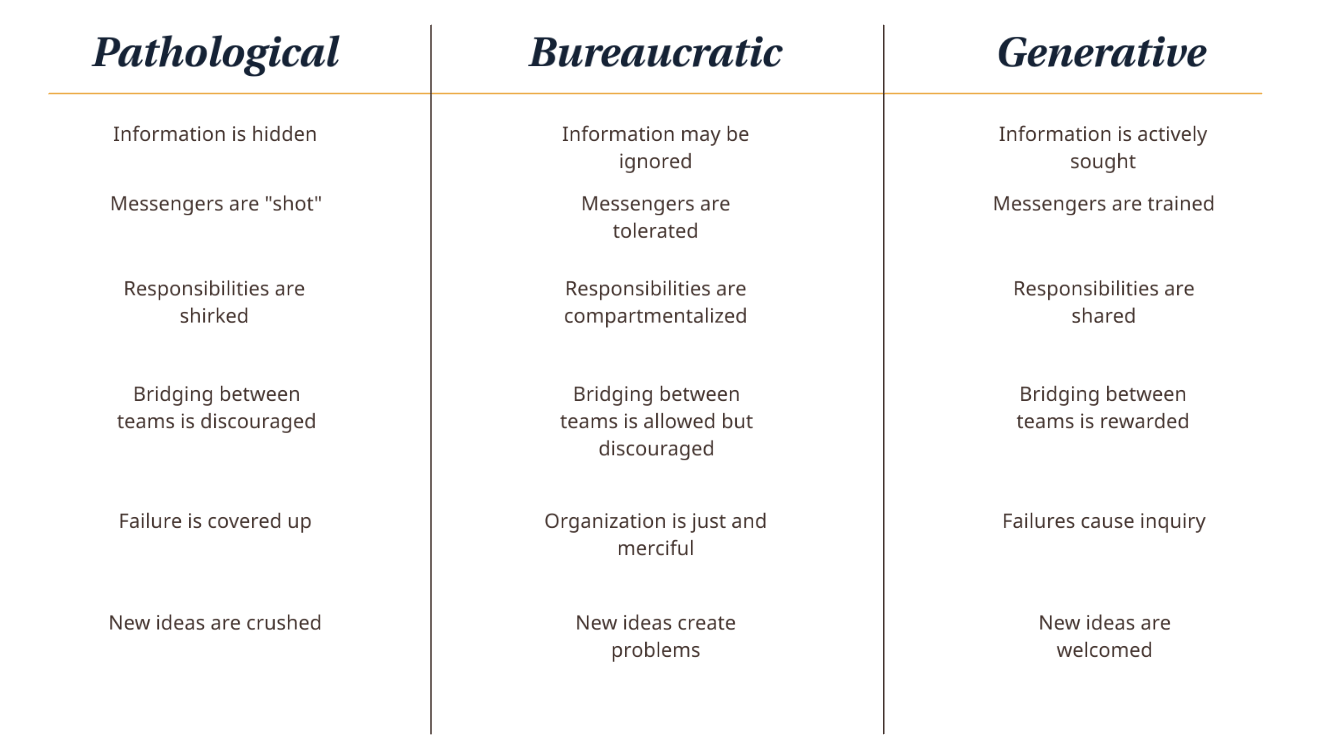
By contrast, teams that treat mistakes as expected, normal, and worthy of discussion develop a very different kind of resilience. They can absorb shocks, they recover faster, and they fucking talk to each other.
Psychological safety isn’t a luxury; it’s infrastructure. It’s what allows a team to bring forward difficult truths. To say, “This model doesn’t work.” To ask, “Can we try something different?” To admit, “We made a wrong assumption back there.” When failing forward becomes the norm, you replace the performance of perfection with the practice of progress. In critical projects, that’s not a compromise: it’s the only way through.
3. Guiding Principles for Failing Better
Failing forward is not just an attitude; it’s a design strategy. But like any strategy, it needs structure. Over time, I’ve come to rely on a few principles that help teams move from the abstract idea of “learning from failure” to the concrete mechanics of failing well.
These aren’t commandments. They’re orientation tools. A way to stay grounded when the work gets messy… which it always does.
3.1. Frame Failure as Feedback
The first, and maybe the most important, is this: failure is feedback. Nothing more, nothing less.
When we stop framing errors as moral failings or intellectual weaknesses, they become what they’ve always been: data. A failed export tells you something about a misaligned naming convention. A broken script flags an unanticipated edge case. A confusing coordination meeting? That’s feedback too: maybe your documentation isn’t as clear as you thought.
If you frame mistakes as diagnostic tools, your instinct shifts from defensiveness to curiosity. The question isn’t “Who messed up?” It’s “What is this telling us?”

3.2. Create Low-Cost Tests
In workshop environments, I always encourage teams to build the smallest thing that can fail. Not the full solution. Not a beautiful model. Just a sliver – a structural detail, a naming protocol, a file exchange -that tests the critical assumptions of the workflow.
The earlier and cheaper your tests, the less painful your pivots.
And that’s the goal: fail small so you can pivot big. Test alignment early. Build standards collaboratively. Prototype naming conventions before enforcing them. Break the system gently and often, so it can evolve into something resilient.
This isn’t inefficiency. It’s strategic agility.

3.3 Cultivate a Culture of Transparency
No principle works in isolation: failing better depends on culture. If the team believes that failure will be punished – or worse, ignored – they’ll hide it. And what’s hidden doesn’t get fixed.
If you can cultivate a space where people feel safe sharing broken files, awkward questions, and ugly first drafts, something else starts to happen. Knowledge flows. Assumptions surface. Friction becomes creative tension, not interpersonal conflict.
That kind of transparency isn’t automatic. It needs modelling. It starts with leaders saying, “I missed something here,” or “This didn’t work the way I thought it would.” It needs rituals: post-mortems, shared folders of lessons learned, permission to be unfinished.
Revisions aren’t a sign you got it wrong. They’re a sign the work is alive.

Closing Thoughts: Fail, Archive, Repeat
If there’s one habit that’s helped me the most – more than any software, workflow, or framework – it’s this: I keep a failure repository. And trust me, it’s plumpy.
Not a shame file. Not a graveyard of broken things. An archive: something structured, alive, itemised. A place where I collect the clash reports that triggered three weeks of debate, screenshots of errors I didn’t understand at the time, models that failed spectacularly because someone (usually me) assumed “the others would follow the standard,” e-mails of people triggering weeks of crisis with clients and suppliers.
It’s not about self-flagellation. It’s about memory.
Because the truth is: failure fades, or at least I hope it does for you. If it doesn’t, it’s called trauma, and that’s a conversation for another time. When memory fades, we lose what it taught us; we forget how long it took to align those levels, why we standardised naming protocols in the first place, or what that terrible export bug revealed about our assumptions.
But when you archive the story of a failure – not just the fact that it happened, but what it changed – it becomes part of your institutional wisdom. It gives the next person (or the next version of you) a head start. More importantly, it reframes the narrative. What didn’t work isn’t a footnote or a source of embarrassment. It’s the precondition for what eventually did. It’s part of the creative residue of the project.
If you’re working digitally, iteratively, collaboratively, you’re not failing if you’re adjusting. You’re not behind if you’re learning. You’re not unprofessional if you’re willing to share the parts that didn’t go as planned.
This isn’t a post about getting it right. It’s a post about getting it better and the messy, revision-filled, emotionally complex process that takes us there. And if we can learn to celebrate the parts of the process that fall apart, we might just start building things that hold up even better.
So fail. Archive. Repeat. That’s the loop. That’s the craft.






No Comments