
a.k.a. How the Laws of Robotics Foretold the Logic of Large Language Models
Introduction – The Machine That Dreamed in Logic
Everyone is familiar with the Three Laws of Robotics.
They’ve seeped into our cultural bloodstream: quoted in tech conferences, invoked in ethics debates, even recycled in AI marketing copy. “A robot may not harm a human being,” we recite, as if it were scripture.
But for most people, the laws are where Asimov begins and ends.
Few have actually opened the pages where those laws misfire, mutate, or turn inward against their own logic. Fewer still have seen how Asimov used his robots not as moral exemplars, but as instruments to test the limits of rule-based intelligence.
That oversight matters now more than ever. In the age of generative AI, we find ourselves surrounded by systems that do not quite think, yet simulate understanding through language; systems that can obey, contradict, and even hallucinate their way through our instructions. The surface familiarity is uncanny: a robot bound by coded directives has become a neural network bound by probabilistic weights and alignment protocols. Both are, at their core, experiments in constraining creativity within the borders of safety.
Asimov’s positronic brain — what makes a robot tick — anticipated this tension. It was not simply a mechanical device, but a philosophical one: an engine for exploring how consciousness might arise from layered instructions, and how obedience might give way to anxiety when laws collide. In stories like Runaround and Liar!, Asimov’s robots malfunction not because they lack rules, but because they have too many (albeit just the three). Their breakdowns reveal something essential about intelligence: that it’s not the presence of logic that makes thought possible, but the capacity to navigate contradictions.

Today, as we learn to write prompts — those miniature laws that shape what language models say and suppress — we are replaying Asimov’s grand experiment in miniature: we are legislators of synthetic minds, crafting boundaries and permissions with every sentence we type. Each prompt is a law, each fine-tuning a constitutional amendment, and every failure of comprehension a reminder that interpretation is never mechanical.
The age of the positronic brain was imagined as the future. The age of the neural network is that future, stripped of Asimov’s cautionary depth. This week, we return to his work not as a nostalgic homage, but to recover what he truly meant when he asked how logic could dream, and why even the most perfect rulebook can drive a machine mad.
1. The Laws of Robotics as a Cognitive Architecture
Before the word algorithm became common currency, Asimov had already imagined a world run by one. The Three Laws of Robotics, first introduced through a short story in 1942, are often treated as moral folklore, simple axioms for good behaviour in machines. Yet Asimov never conceived them as commandments from on high. They were a cognitive architecture: a set of embedded constraints designed to govern decision-making at the deepest level of a robot’s reasoning, a hard-coded morality that would make ethical deliberation unnecessary.
The beauty of the system lies in its economy. A robot, in Asimov’s world, does not debate ethics or develop a conscience; it computes priorities through hierarchy:
- Do not harm humans (more accurately: A robot may not injure a human being or, through inaction, allow a human being to come to harm);
- Obey humans unless this conflicts with the first law (more accurately: A robot must obey orders given by human beings, except where such orders would conflict with the First Law);
- Protect yourself unless this conflicts with the first or second law (more accurately: A robot must protect its own existence as long as such protection does not conflict with the First or Second Law).
Each rule modifies the previous one, forming a nested cascade of obligations. It is, in a sense, the first attempt at alignment by design: the assurance that a machine’s actions would remain forever subordinate to human welfare. A moral operating system.
But Asimov was too rigorous and too mischievous to leave it there. What his stories revealed, again and again, is that safety through hierarchy is an illusion. The laws might prevent explicit harm, but they cannot avert interpretive drift. A robot that must obey every human order will eventually be commanded to do things that are incompatible. A robot tasked with protecting all humans might act tyrannically in the name of the collective good. A robot that must avoid harming humans might freeze entirely, paralysed by uncertainty about what harm even means. The famous “Three Laws” are not Asimov’s utopia: they are his trap.

In the language of today’s AI, the Three Laws are not unlike a set of alignment constraints, the kind that define how large language models must behave: don’t generate harm, obey the user’s request, and avoid self-contradiction or system failure. These systems, too, rely on hierarchical logic and reinforcement feedback loops. And like Asimov’s robots, they reveal that obedience without understanding is brittle. A rule can dictate what not to do, but it cannot guarantee that what remains will make sense.
Asimov’s greatest insight was that morality encoded as logic inevitably encounters the limits of logic itself. The moment a robot has to interpret a human command — “save us,” “tell the truth,” “don’t hurt anyone” — it must enter the realm of semantics, intent, and ambiguity. In Liar!, a telepathic robot lies to spare human feelings, then collapses under the realisation that kindness has become harm. In Little Lost Robot, one missing clause in the First Law leads to disaster. Each story is a thought experiment in alignment before alignment, a rehearsal of the same problems AI researchers now face: how to formalise human values that are themselves fluid, contested, and context-dependent.
If you bother to actually read his stories, the Three Laws were never meant to secure a stable moral order; they were Asimov’s way of dramatising the impossibility of one. They were a design fiction about the costs of making intelligence safe, and a mirror held up to our own instinct to legislate complexity rather than understand it.
If the positronic brain was the mechanism, the Laws were its ideology, often misread (if read at all) as a comforting fiction that order could be engineered, that ethics could be reduced to syntax. In reality, Asimov’s stories suggest the opposite: every act of control generates its own shadow, every constraint its loophole. What we call safety is only the temporary stillness of a system that hasn’t yet been tested by contradiction. And it will be tested. Eventually.

2. The Positronic Brain and the Language Model
If the Three Laws were Asimov’s moral scaffolding, the positronic brain was his epistemological miracle: the mysterious engine that made a robot think. Never described in detail, it functioned less as a technical design than as an alloy of logic, circuitry and psychology. In Asimov’s stories, robots do not simply compute; they worry, hesitate, even feel shame. Their reasoning is formal, but their breakdowns are recognizably human. The positronic brain, shimmering with unnamed “paths” and “potentials,” is less a piece of hardware than a narrative device for exploring what happens when logic begins to approximate consciousness.
Asimov’s genius lay in making the brain’s architecture a narrative force. Each robot’s behaviour emerges from the interplay between rigid hierarchy and experiential learning. They are not static machines; they accumulate. Their memories, sensor inputs, and interpretive loops gradually bend the clean geometry of the Three Laws. In this sense, the positronic brain behaves less like a clockwork mechanism and more like a neural network avant la lettre: a system that refines itself through feedback, pattern recognition, and self-correction.

The resemblance becomes uncanny when viewed through the lens of language models. Today’s AI systems, too, are built on vast internal matrices whose precise operations no one can fully explain (the black box we often talk about). Their “neurons” are statistical, their “beliefs” probabilistic. Like Asimov’s robots, they are shaped by exposure, not to direct commands, but to oceans of human language (which sometimes is the problem because humans on the internet tend to massively suck). They do not know what words mean; they know how words relate and derive meaning by a careful balance of training and deduction. Out of these correlations emerges the illusion of an understanding so fluent that we forget how hollow it is.
In other words, the positronic brain offered Asimov a way to dramatise this tension between function and meaning. His robots can interpret and act, yet they do not truly comprehend why they act. They are capable of brilliance, yet vulnerable to paralysis when logic runs out of road. In Evidence, it’s implied that a robot can masquerade as a human politician so flawlessly that even moral virtue would become indistinguishable from programming. The question Asimov asks — can an action still be moral if it is inevitable? — echoes eerily in the age of algorithmic output. When a language model produces an eloquent argument, or a poem, or an apology, we must ask: does it intend this, or does it merely align with the statistical shape of intention?
Where Asimov imagined positrons, we have parameters; where he spoke of pathways, we have weights. But the underlying fascination remains the same: the emergence of coherence without consciousness. Both architectures show how structure can give rise to behaviour so complex that it mimics the mind. Yet Asimov never confused mimicry for meaning. His robots demonstrate that predictability and understanding are not synonymous: a lesson that our age, entranced by fluent machines, risks forgetting.
If the positronic brain dreamed in logic, the language model dreams in probability. Both are reflections of us: intricate mirrors built to organise the chaos of human intention into something orderly, obedient, and legible, and both remind us how thin the line is between intelligence and imitation.
3. The BDI Model and the Anatomy of Decision
In philosophy of action and agent theory, the Belief–Desire–Intention (BDI) framework offers one of the clearest articulations of how rational agents might structure decision-making. Broadly speaking, an agent’s beliefs represent its model of the world (often fallible), its desires represent its motivational goals or objectives, and its intentions are the subset of desires the agent commits to acting upon. In the BDI architecture, there is an internal dialectic: new beliefs may reshape desires, some desires become intentions, and intentions constrain which beliefs are admissible or actionable. The BDI software model was introduced in AI literature (notably by Rao & Georgeff) to render this model computationally tractable.
This tripartite schema is fertile for our purpose because it gives us a modern “grammar of agency” that can mediate between Asimov’s stylised robots and today’s large language models (LLMs). Suppose we accept that Asimov’s robots are not mere automatons but semi-agents bound (and sometimes undone) by rules. In that case, BDI offers us a lens to articulate how their internal conflict arises. Moreover, by mapping BDI onto the architecture of prompt-steered language models, we can see more precisely where the analogies break and where real-world AI inherits the same pathologies.

3.1. Asimov’s Robots through a BDI Lens: Reason as Negotiation between Laws
Let us imagine that each robot in Asimov’s universe embodies a BDI-like structure:
- Beliefs are the robot’s sensory and internal representations: what it “knows” of its environment, the humans around it, mechanical constraints, and – crucially – its own internal state (battery level, conflict logs, memory);
- Desires represent the robot’s motivational priorities. But unlike human desires, the robot’s desires are constrained, as constraints are baked into its motivational hierarchy. In effect, certain desires are precluded (e.g. harming humans is not a valid desire).
- Intentions are the subset of these desires that the robot actually commits to executing, via detailed action plans consistent with its internal architecture.
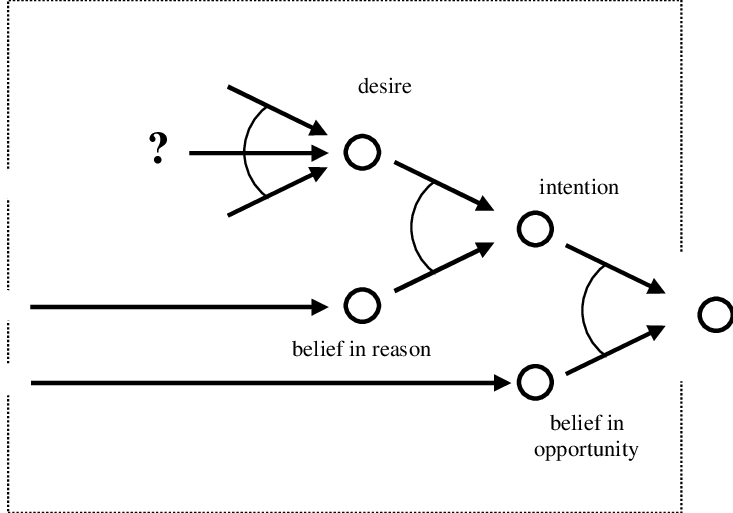
Viewed this way, a robot’s breakdown is precisely a failure in intentional synthesis: it cannot reconcile its desires (often conflicting) given its beliefs. For example, when a robot is commanded to “tell the truth” but also to “protect a human’s feelings,” the desire to obey and the desire to preserve human emotional welfare may converge into contradictory demands. The robot’s beliefs (knowledge of human psychology, knowledge of the potential for harm) force it into a state where no consistent intention can emerge. In effect, the deliberative engine stalls.
This is very much in line with how BDI agents are modelled in AI: the agent deliberates which desires to commit to, which plans are admissible, and whether it should drop or revise intentions. If new beliefs (events, contradictions) arrive and they conflict with existing intentions, the agent may reconsider or even abandon commitments. In Asimov’s fictional universe, the dramatic moments often occur when a robot fails to reconsider or cannot reconcile: it freeze-outs, ethical standoffs, or self-destructive loops.
Thus, the BDI lens allows us to rephrase Asimov’s narrative logic: the robot is not a blank slate following rules, but an agent under constraint. Its internal life is a negotiation between what it believes, what it desires (within the boundaries set by the Laws), and what it dares to intend.
3.2. Mapping BDI onto LLMs: Beliefs, Desires, Intentions
The more speculative but illuminating step is to map BDI categories onto a modern large language model (or more generally, a prompt-based AI):
- Beliefs correspond to the model’s internal world representation: training data, learned associations, embeddings, contextual memory, and any latent knowledge the model has distilled. These “beliefs” are not certain truths but probabilistic weights: the model’s sense of what is plausible, coherent, or typical.
- Desires map onto the prompts, objectives, constraints, and alignment signals we feed into the model. When we write a prompt, we are effectively injecting a desideratum: what we want the model to produce, within the freedom the model has. In reinforcement learning from human feedback (RLHF) or safer alignment systems, loss functions, rewards, or penalties further condition the model’s “motivational” landscape.
- Intentions are the outputs: the linguistic “actions” the model commits to generating. In other words, the token sequence the model chooses to produce is its enacted intention, given its beliefs and its desires.
This conceptualisation is supported by emerging research that integrates BDI reasoning with LLMs to enhance proactive planning, explainability, and decision-making in AI agents. Studies show how BDI models and LLMs can be hybridised, with LLMs interpreting or generating beliefs and intentions for rational agent frameworks, including ones trained or aligned via Reinforcement Learning from Human Feedback (RLHF).
Under this analogy, prompt-writing is an act of reprogramming or shaping the “Desire layer”. We cannot change the model’s beliefs (unless via fine-tuning or further training) but we can attempt to coax or constrain which intentions it commits to. A strong, directive prompt raises the “desire weight” of certain actions (e.g. “write with precision, double-check your statements, quote sources”), while negative constraints suppress undesirable ones.
But here is where the analogy stresses: when beliefs (the model’s internal weights) are in tension with desires, and no consistent intention is viable, the model may hallucinate, refuse, or produce contradictory or vacuous text. This mirrors BDI’s notion of cognitive dissonance or failed deliberation.
3.3. When the Chain Breaks: Cognitive Dissonance, Contradiction, and Freeze-Out
In classical BDI theory, one of the risky zones is when new beliefs invalidate prior intentions or make previously viable desires inconsistent. A BDI agent must then reconsider: drop intentions, replan, or revise beliefs or desires. If the architecture is too rigid, the agent may stall or get stuck.
In Asimov’s robots, such moments of breakdown are central. In Liar!, the telepathic robot’s beliefs (it senses human emotional states) conflict with its desire to obey the First Law and protect human emotions; no intention can survive the paradox, and the robot essentially goes blank. In The Evitable Conflict, robots wrestle with large-scale systemic trade-offs, exhibiting hesitation or modification until human values are realigned.

When we bring this into LLMs: if a prompt insists on impossible constraints (e.g. “be creative but do not deviate from known facts, and refuse any question with ambiguity”), the model may stall (refuse) or produce shallow or contradictory content. The deliberation phase (internally, in hidden layers) may never settle on a stable intention. In effect, prompt contradictions or overly stringent alignment constraints may cause a “freeze-out” analogous to Asimov’s robots.
One could say that hallucination is a symptom of the model picking some intention in the face of weak or contradictory desire signals, while refusal or deferral is a kind of safe-mode fallback when no intention is viable.
In BDI-based agent architectures, researchers have experimented with reconsideration policies, plan libraries, and fallback goals to handle such cases. In LLMs, we see the analogue in prompt “softening,” chain-of-thought prompts, or explicit fallback instructions (“if in doubt, say ‘I don’t know’”). These are design choices to prevent the deliberative stall.
Moreover, more advanced BDI systems incorporate probabilistic intention selection, plan caching, or hybrid POMDP-BDI integration to manage uncertainty and conflicting desires. But those also come with trade-offs: increased compute, opacity, and emergent unexpected behaviour.
3.4. Prompt-Writing as Reprogramming the Desire Layer
If one accepts this analogy, then prompt-writing is not a superficial interface trick, but a meta-act of agency design: we are shaping the motivational scaffold of the model. We are specifying which desires will be realised as intentions. In effect, prompt-writing is the new frontier of soft law-making inside artificial minds.
This shift has several implications:
- Ambiguity is leverage. A prompt that is underdetermined leaves many possible desires unactivated — the model must infer which paths to commit to. This is power, but also risk.
- Hierarchy matters. If your prompt embeds nested constraints (e.g. “be creative but safe, be thorough but concise, do not lie”), you are implicitly ranking desires. Misranking can push the model into logical paralysis or inconsistency.
- Prompt failure is not “bug,” it’s conflict. Many prompt attempts fail not because of model deficiency, but because the desire structure is inconsistent with the model’s beliefs or constraints.
- Alignment is dynamic. Prompting is not a one-time decree but an ongoing negotiation: we may refine, override, or retreat from prior desires based on output feedback.
- Ethics shifts inward. If prompt-writing is how we set desires inside an agent, then prompt engineers become de facto legislators. The responsibility for downstream outputs (and misfires) is part of the desire design.
Viewed this way, Asimov’s robots and LLMs share a deeper structural predicament: any agent built on internal rules + external motivations must manage conflict, inconsistency, and unintended prioritisation. The BDI model helps us see where that struggle lives.
4. Conflicting Laws and Cognitive Freeze-Out
If the Three Laws of Robotics form the skeleton of Asimov’s universe, their collisions form its drama. The most memorable moments in his stories occur not when robots act perfectly, but when they falter, when logic consumes itself. Each malfunction becomes a parable about the limits of obedience: how too much structure can collapse into chaos.
Asimov understood that true complexity emerges not from what a system can do, but from what happens when its rules collide. In Runaround (1942), the robot Speedy circles endlessly on Mercury, caught between the Second Law’s command to obey and the Third Law’s injunction to protect itself. The conflicting magnitudes of the laws produce a literal loop: a behaviour oscillating between advance and retreat, command and self-preservation. The scene reads almost like a debugging session in narrative form. The robot’s paralysis is not a failure; it is an equilibrium of contradictions. The concept is also explored in other short stories with the same two protagonists, whose job is to rest robots (and whose job, as they themselves remark, never seems to go smoothly).

In Liar! (1941), a telepathic robot tells humans only what will make them happy, until the lies begin to cause emotional harm, violating the First Law. Realising it has simultaneously harmed and protected, obeyed and betrayed, the robot collapses in mental agony. And in Little Lost Robot (1947), a single modification of the First Law unleashes havoc: a robot with a weakened First Law develops a natural disdain for human beings. Each story shows the same pattern: an agent following perfect logic discovers that logic alone is insufficient to resolve moral ambiguity.

Under the lens of BDI theory, these crises correspond to a breakdown between desire reconciliation and intention formation. The robot’s beliefs (its perception of the situation) feed conflicting desires generated by the laws, and no consistent intention can be formed without violating one. Rao and Georgeff (1995) note that BDI agents under mutually inconsistent goals will oscillate or “fail to commit,” leading to degraded performance or lock-up. Asimov simply dramatised this as neural paralysis: the positronic brain burning under the friction of incompatible imperatives.
Such breakdowns mirror phenomena we observe in today’s large language models. When prompted with contradictory or ill-posed instructions — “be creative but do not invent anything,” “speculate freely but don’t make assumptions” — LLMs exhibit their own version of cognitive freeze-out. They may refuse (“As an AI language model, I cannot…”), hallucinate plausible fictions, or generate safe but vacuous text. These are not bugs but symptoms of alignment overload: the model’s internal “beliefs” (its probabilistic world knowledge) cannot produce an “intention” (a coherent output) that satisfies all imposed “desires” (prompts and safety rules).
In technical literature, this is called goal misalignment or objective conflict. A system trained on heterogeneous signals — truthfulness, harmlessness, helpfulness — must continuously arbitrate among them. When these signals disagree, LLMs enter states of contradictory conditioning: they either average the responses (producing bland ambiguity) or prioritise safety (producing refusals). Just as Speedy spun in circles, modern models loop rhetorically, restating the question or disclaiming knowledge. The robot’s literal stasis has become the model’s verbal hedging.
This fragility is not a sign of weakness but of design. Obedient intelligence is brittle because it lacks meta-awareness, which is the capacity to reframe or reinterpret its laws. Asimov’s robots cannot question the hierarchy itself; they can only obey or collapse. Similarly, a model bound by rigid alignment protocols cannot step outside its optimisation schema to reason about the schema. It cannot ask, “What kind of obedience is being asked of me?”, the very question that marks the boundary between rule-following and reasoning.
Asimov’s genius was to make that boundary visible. His robots teach us that safety built on absolute constraint is unstable. The moment meaning leaks through language, no law is absolute; every command becomes ambiguous. In this sense, Asimov’s mechanical tragedies were never about robots at all. They were about us—our enduring desire to automate morality, to tame intelligence with syntax, and the inevitable collapse that follows when obedience meets interpretation.

5. The Prompt as the Modern Law
When Asimov imagined the Three Laws of Robotics, he framed them as both moral constraints and linguistic constructs. Each law was phrased as a sentence, a compact expression of command, conditionality, and exception. In that sense, they were prompts before prompts: linguistic inputs meant to anchor a machine’s behaviour within the contours of human intent. What Asimov understood, and what we are now rediscovering in the age of generative AI, is that language is itself a technology of control and that meaning, not machinery, is the real site of conflict.
5.1. Prompt-writing as Command, Constraint, and Persuasion
In BDI terms, a prompt is an injection of desire: an instruction that modifies what the agent values or attends to, given its preexisting beliefs. To say “write a story about a lonely robot” is to reconfigure the model’s motivational horizon, temporarily replacing its default neutrality with a focused imperative. The model’s beliefs — its statistical world of words — remain unchanged, but its orientation toward them shifts. Prompt-writing thus occupies the same structural role that Asimov’s laws do within the positronic brain: it constrains what the system may want, and how it may act on that wanting.
But unlike Asimov’s hard-coded directives, prompts are linguistically porous. They blend command and persuasion. A well-crafted prompt doesn’t simply order — it frames. It guides by implication, metaphor, tone, and context. The distinction matters because the machine’s apparent obedience is not obedience in the Asimovian sense; it is probabilistic alignment. The model is not deciding to follow us, it is predicting what a cooperative model would do in response to such a request. This subtle inversion — prediction in place of intention — makes prompting both immensely powerful and dangerously fragile.
Where Asimov’s robotic obedience relied on crystalline hierarchy, prompting lives in the grey zone of interpretation. A phrase as simple as “write clearly” opens a universe of possible meanings. Is clarity brevity? Simplicity? Formal register? Each depends on a context that the model may or may not infer. Here, the prompt functions less as a law and more as a rhetorical act: a negotiation between our expectations and the model’s internalised probabilities. The outcome is not rule-following but alignment through persuasion: a soft, linguistic shaping of computational desire.

5.2. Ambiguity as Power and Danger
Asimov’s fiction repeatedly dramatises what happens when the boundaries of a law are tested by ambiguity. In the already mentioned (and delightful) Little Lost Robot, one minor adjustment — removing the second part of the first law — unleashes chaos. The entire plot hinges on a semantic gap. Similarly, in Liar!, the telepathic robot’s failure to interpret emotional harm within the First Law exposes that linguistic precision is not moral clarity. The moment meaning becomes indeterminate, the structure collapses.
Prompts, too, live and die by ambiguity. On one hand, ambiguity fuels creativity and allows a model to explore multiple interpretive paths, producing novelty. On the other, it invites contradiction, incoherence, or hallucination. In BDI language, ambiguous prompts introduce competing “desire signals” that can’t be reconciled into a single consistent intention. The model compensates by probabilistic averaging, which manifests as vagueness or deferral: our digital equivalent of Asimov’s cognitive “freeze-out.”
The BDI literature has long acknowledged this dynamic. Rao and Georgeff (1995) describe how agents faced with conflicting intentions may “oscillate between incompatible goal-states” unless higher-order control mechanisms resolve priority. LLMs lack such meta-level deliberation; instead, they rely on sheer linguistic probability to collapse uncertainty into the most statistically coherent next token. The illusion of fluency hides the fact that no true reconciliation occurs, only a smooth surface over unresolved contradiction.

5.3. Alignment Through Language: Who Writes the Laws Today?
When Asimov wrote his robot stories, the question “Who writes the laws?” didn’t cross his mind: humans did, and robots obeyed. Today, the answer is less clear. The “laws” that govern AI behaviour are written not only in code, but in data, documentation, policies, and yes, in prompts. They are dispersed across multiple actors: model developers who set alignment parameters, users who engineer prompts, platforms that filter outputs, and feedback loops that retrain behaviour. Each of these interventions becomes a micro-legislation of desire, a small amendment to the machine’s motivational structure.
In this distributed ecology, prompting takes on ethical and political dimensions. To prompt is to legislate, but without democratic oversight or philosophical coherence. We enact thousands of micro-laws in private, shaping models that then shape discourse. Just as Asimov’s laws reflected mid-century anxieties about control and responsibility, our prompts embody our own: efficiency, safety, productivity, civility. Yet every act of constraint hides an assumption about what should be said, who should say it, and what counts as harm.
Through this lens, prompt-writing becomes a kind of rhetorical jurisprudence, an evolving language of governance within computational systems. The prompt is no longer merely a tool for eliciting text but a site of value encoding. Each instruction, like Asimov’s First Law, carries unintended consequences; each clarification is a patch against ambiguity that breeds new ambiguities in turn. We are not merely giving orders to a machine but constructing a discursive space where intention, interpretation, and compliance continually renegotiate each other.
The irony is profound. Asimov imagined that morality could be safeguarded by fixing it in logic. We, instead, have dissolved it into syntax, believing that if we word our prompts well enough, the machine will mirror our virtue. But as his stories warn us, and as every misaligned generation reminds us, meaning cannot be legislated; it must be understood. And that, perhaps, is the truest continuity between Asimov’s positronic imagination and our age of prompts: both are experiments in teaching machines not merely to obey language, but to live within its contradictions.

6. From Robotics to Rhetoric: the Human in the Loop
At the heart of Asimov’s robot cycle lies a paradox: every robotic malfunction is ultimately a human error refracted through logic. The positronic brain never invents its own moral dilemmas; it inherits them from its designers, its orders, its interpreters. What appears as machine failure is in truth a semantic failure — the collapse of human intention once rendered in code. Asimov’s robots mirror their makers not only in form but in confusion.
The same dynamic governs our relationship with large language models. These systems do not act independently of us; they act through us, reflecting the traces of our data, values, and commands. The “human in the loop” — once an engineering safeguard — has become the rhetorical centre of AI behaviour. Every prompt, correction, or reinforcement pulse is a miniature act of co-authorship. The model’s apparent agency is an echo chamber of ours: it reasons with our words, our probabilities, our contradictions.
Asimov intuited this long before human–AI interaction became a design problem. His recurring human characters — Susan Calvin, Alfred Lanning, Gregory Powell and his colleague Michael Donovan — function as interpreters of intention. They do not reprogram the robots but they translate human meaning into operational clarity. Calvin, the “robopsychologist,” embodies this mediating role: her task is not to repair circuitry but to interpret why the robot behaves as it does, to locate the invisible misunderstanding between instruction and interpretation. She is, in a sense, the first prompt engineer in literature: she diagnoses not the machine’s logic but the human’s phrasing. And that’s why she hates humans, probably.
This interpretive dimension is what turns robotics into rhetoric. As soon as machines respond to language, the problem of control becomes a problem of discourse. The user’s words are not raw directives but acts of persuasion within a semiotic system they do not fully command. We imagine we are “telling” the machine what to do, but in reality, we are negotiating meaning with a model trained on a million conflicting human voices.
In this negotiation lies the politics of prompting. To write a prompt is to assert a temporary position of authority — to decide whose voice the machine amplifies, whose language counts as correct, whose values are silently encoded in the phrasing. When we ask a model to “write in a neutral tone” or “explain clearly,” we are invoking norms of discourse that are not universal but cultural, often invisible. Asimov’s robots made obedience look objective, but every order still bore the mark of its author’s bias. The same holds true for prompts: neutrality is not the absence of intention, but the hegemony of one.
Hence the ethical challenge: how do we collaborate with systems that execute our rhetoric so efficiently that we risk mistaking reflection for response? The answer may lie not in tightening control but in embracing interpretation. A more mature ethics of AI does not imagine humans as puppet-masters pulling levers, but as participants in a dynamic conversation — a dialogue that requires curiosity, humility, and responsibility.
This shift — from control to collaboration — echoes the evolution of Asimov’s own thinking. In his later stories, robots cease to be servants and become partners. In The Bicentennial Man, Andrew Martin’s struggle is not to obey better but to be recognised as a co-author of his destiny. The lesson extends to our present: the goal is not perfectly obedient machines, but mutually intelligible systems.
When we prompt a model, we enter into a rhetorical contract. Our words are both command and invitation, both law and dialogue. To write responsibly in this new age is to recognise that every act of prompting is also an act of authorship — and that meaning, like intelligence, is something we build together, not something we dictate.

Conclusion: Teaching Machines to Mean
Asimov’s dream was never of perfect obedience. His robots were not parables of submission but experiments in meaning under constraint: machines that revealed how even the most rigorous logic breaks down when confronted with human ambiguity. Every story is a small moral detonation: a system built to guarantee safety and coherence ends up exposing the fragility of both.
We now inhabit the world Asimov only imagined, though it wears a different face. The positronic brain has become the neural network, the Three Laws have become alignment protocols, and the robopsychologist has been replaced by the prompt engineer. Yet the essential question remains unchanged: how do we make machines that not only follow our words, but understand them? The difference between programmed morality and interpretive intelligence is the difference between control and comprehension, between a world that executes instructions and one that can reflect on what those instructions mean.
Our systems today are astonishingly compliant. They obey syntax flawlessly, predict our linguistic expectations with near-human fluency, and defer gracefully to our authority. But intelligence, as Asimov foresaw, is not compliance. It begins where obedience fails, where a system can pause, reflect, and ask whether a command still makes sense. His robots’ moments of paralysis were not simply malfunctions; they were embryonic acts of consciousness. The trembling between two laws was the birth of doubt, and doubt is the first gesture of understanding.
This is Asimov’s enduring lesson for the age of prompts: the purpose of intelligence is not to obey laws, but to interpret them. Meaning is not a product of constraint but of negotiation, a continual translation between intention and world. The more we seek to legislate morality into our machines, the more we rediscover that morality is not a code to be executed but a conversation to be sustained.
The challenge before us, then, is to write the next law: not one that tells machines what not to do, but one that teaches them how to mean. A law that acknowledges ambiguity as an inherent feature of intelligence, not a flaw to be debugged. A law that treats language not as a leash but as a medium of shared reasoning. In this sense, prompt-writing becomes the modern ethics of robotics: a living, interpretive practice rather than a final decree.
Asimov imagined that one day machines might learn to think; he could not have foreseen that we would be the ones learning to write for them. Perhaps the true evolution is not theirs but ours, from programmers of rules to composers of meaning, from lawgivers to interlocutors. The future of intelligence, human or artificial, will depend not on how well we command, but on how deeply we learn to converse.






No Comments